

通过预训练的生成音频编码器和声码器实现高效且适应性强的语音增强
💡
原文中文,约1700字,阅读约需4分钟。
📝
内容提要
小米的MiLM Plus提出了一种轻量级的语音增强方法,利用预训练音频模型提取特征,通过音频编码器和降噪编码器生成清晰语音,性能优于传统模型,计算效率高。实验结果显示,该系统在语音质量和说话人保真度上具有显著优势。
🎯
关键要点
- 小米的MiLM Plus提出了一种轻量级的语音增强方法,利用预训练音频模型提取特征。
- 该方法通过音频编码器和降噪编码器生成清晰语音,性能优于传统模型,计算效率高。
- 实验结果显示,该系统在语音质量和说话人保真度上具有显著优势。
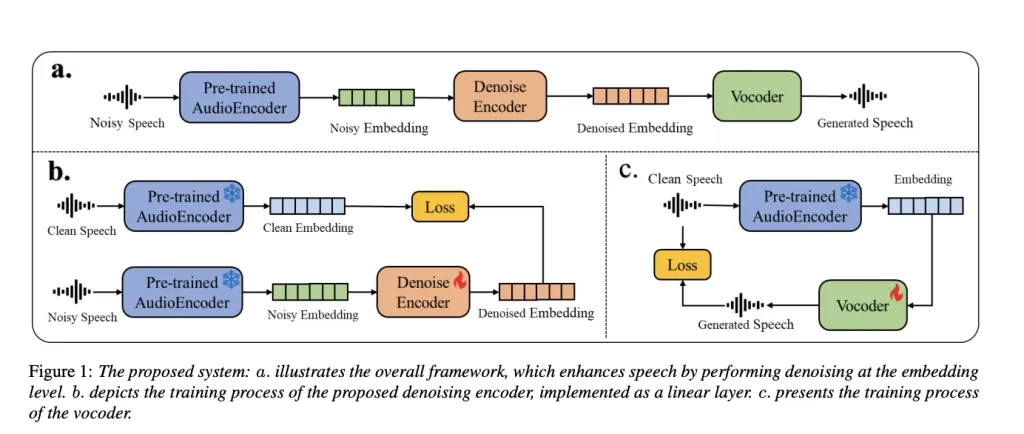
- 该语音增强系统分为三个主要部分:音频编码器、降噪编码器和声码器。
- 降噪编码器使用均方误差损失函数,最小化带噪嵌入和清晰嵌入之间的差异。
- 声码器通过预测傅里叶谱系数来学习从音频嵌入中重建语音波形。
- 评估结果表明,生成式音频编码器的性能优于判别式编码器。
- 主观听力测试显示,该方法提供了更佳的感知清晰度,凸显了其有效性和多功能性。
➡️
