

ICLR 2025 杰出论文:一次训练就能计算数据价值——AI 版权和数据治理的新突破
💡
原文中文,约2500字,阅读约需6分钟。
📝
内容提要
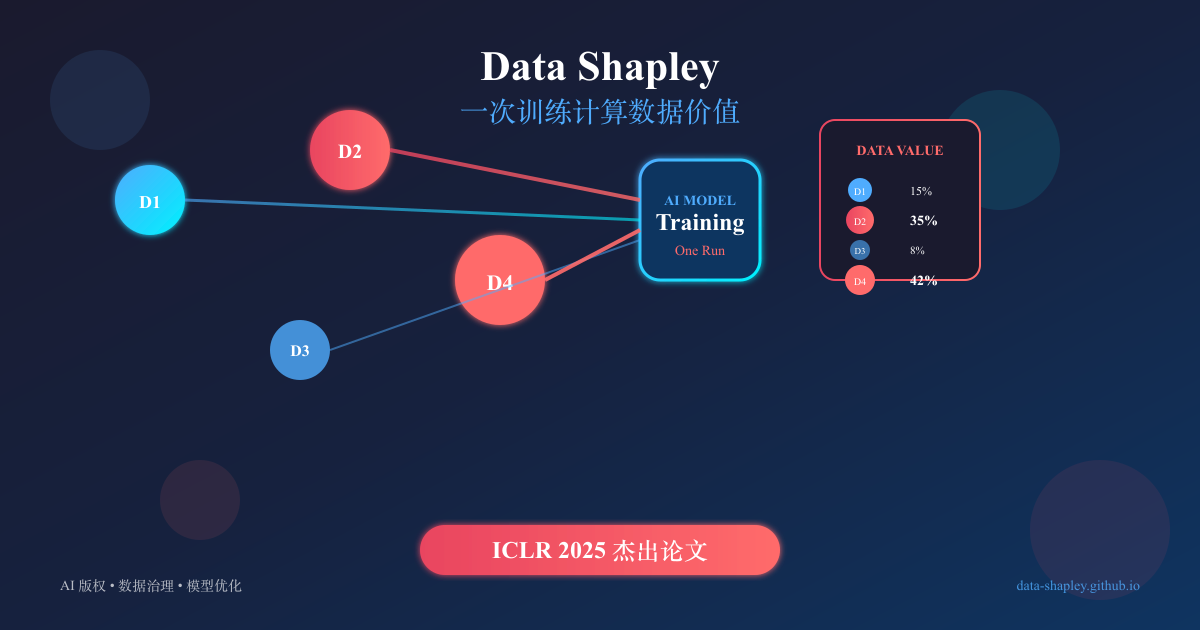
本文提出了In-Run Data Shapley方法,实时追踪训练数据对模型的贡献,解决了传统方法计算复杂度高的问题。研究表明,数据价值在训练过程中会变化,精心策划的数据集可能仍包含负面数据,强调了数据治理的重要性。该方法为AI版权和数据质量提供了新视角,具有广泛的应用前景。
🎯
关键要点
- 提出了In-Run Data Shapley方法,实时追踪训练数据对模型的贡献。
- 解决了传统方法计算复杂度高的问题,适用于大规模模型。
- 数据价值在训练过程中会变化,强调数据治理的重要性。
- 即使是精心策划的数据集仍可能包含负面数据,需进行过滤。
- 该方法为AI版权和数据质量提供了新视角,具有广泛的应用前景。
- 实验结果显示训练数据对生成AI有贡献,可能改变版权评估方式。
- 识别和移除低质量数据,提高模型训练效率和质量。
- 未来可能影响AI版权诉讼、数据市场定价机制和模型训练透明度。
➡️
