
Unbabel 推出 TOWER+:多语言 LLM 高保真翻译与指令遵循的统一框架
内容提要
大语言模型(LLM)推动了机器翻译的发展,但在翻译准确性与指令遵循之间存在挑战。TOWER+模型通过预训练和强化学习实现了翻译与对话能力的平衡,展现出优越的翻译质量和灵活性,适用于多种应用场景。
关键要点
-
大语言模型推动了机器翻译的发展,但在翻译准确性与指令遵循之间存在挑战。
-
TOWER+模型通过预训练和强化学习实现了翻译与对话能力的平衡。
-
模型必须保持术语一致性,并遵循不同受众的格式指南。
-
当前针对翻译准确性定制语言模型的方法包括微调和强化学习。
-
TOWER+模型由多个参数规模的变体组成,旨在探索翻译专业化与通用实用性之间的权衡。
-
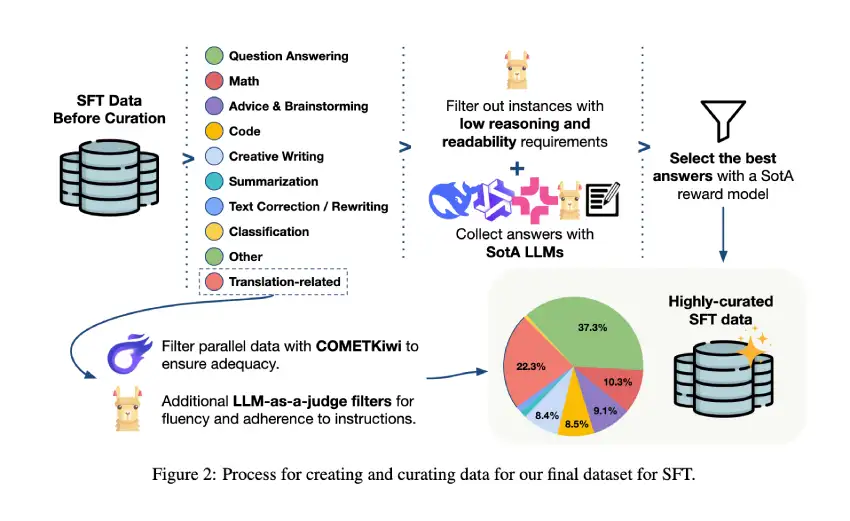
TOWER+的训练流程包括预训练、监督调优、偏好设置和强化学习。
-
TOWER+在多语言通用聊天提示中取得了优异的基准测试结果。
-
TOWER+模型的关键技术亮点包括覆盖多种语言和方言,保持翻译质量与通用能力的平衡。
-
研究提供了一种可重复的方法来构建同时满足翻译和对话需求的语言模型。
-
TOWER+证明了卓越的翻译能力和灵活的对话能力可以在一个开放权重套件中共存。
延伸解读
翻译与指令遵循的平衡
TOWER+模型通过预训练和强化学习实现了翻译准确性与指令遵循之间的平衡。这一特性使其在多种应用场景中表现出色,尤其是在需要同时处理翻译和对话任务的情况下。企业在选择翻译工具时,应关注模型在这两方面的综合表现,以确保满足特定需求。
多语言支持的优势
TOWER+模型支持多达55种语言和方言,展现出其在全球化背景下的适用性。这种多语言能力不仅提升了翻译质量,也为跨国企业提供了更灵活的沟通解决方案。企业在国际化过程中,选择具备广泛语言支持的模型,可以有效降低沟通障碍,提升工作效率。
基准测试结果的重要性
TOWER+在多个基准测试中取得了优异成绩,尤其是在翻译保真度和指令遵循能力方面。这些测试结果不仅验证了模型的性能,也为用户提供了选择依据。企业在评估翻译工具时,应重视这些基准测试数据,以确保所选工具能够满足其业务需求。
延伸问答
TOWER+模型的主要特点是什么?
TOWER+模型通过预训练和强化学习实现翻译与对话能力的平衡,涵盖多种语言和方言,展现出优越的翻译质量和灵活性。
TOWER+模型如何解决翻译准确性与指令遵循之间的挑战?
TOWER+模型通过统一的训练流程,包括预训练、监督调优和强化学习,来平衡翻译准确性与指令遵循能力。
TOWER+模型的训练流程包括哪些阶段?
TOWER+的训练流程包括持续预训练、监督微调、偏好优化和可验证强化学习四个阶段。
TOWER+模型在基准测试中的表现如何?
TOWER+模型在多语言通用聊天提示中取得了33.47%的胜率,并在多个基准测试中表现优于同等规模的开放权重模型。
TOWER+模型的参数规模有哪些?
TOWER+模型有多个参数规模的变体,包括20亿、90亿和720亿参数。
TOWER+模型的应用场景有哪些?
TOWER+模型适用于翻译、代码生成、数学问题求解和问答系统等多种应用场景。
