
Hugging Face 开源 FineVision:一个包含 2400 万个样本的全新多模态数据集,用于训练视觉语言模型
内容提要
Hugging Face 发布了 FineVision,一个包含 1730 万张图片和近 100 亿个答案标记的开放多模态数据集。该数据集经过严格筛选和系统评级,提升了视觉语言模型的训练质量,支持多种新兴任务,减少数据泄漏,推动研究的可重复性和可访问性。
关键要点
-
Hugging Face 发布了 FineVision,一个包含 1730 万张图片和近 100 亿个答案标记的开放多模态数据集。
-
FineVision 是规模最大、结构最完善的公开 VLM 训练数据集之一,聚合了 200 多个数据源。
-
该数据集经过严格过滤和系统评级,提升了视觉语言模型的训练质量,减少数据泄漏。
-
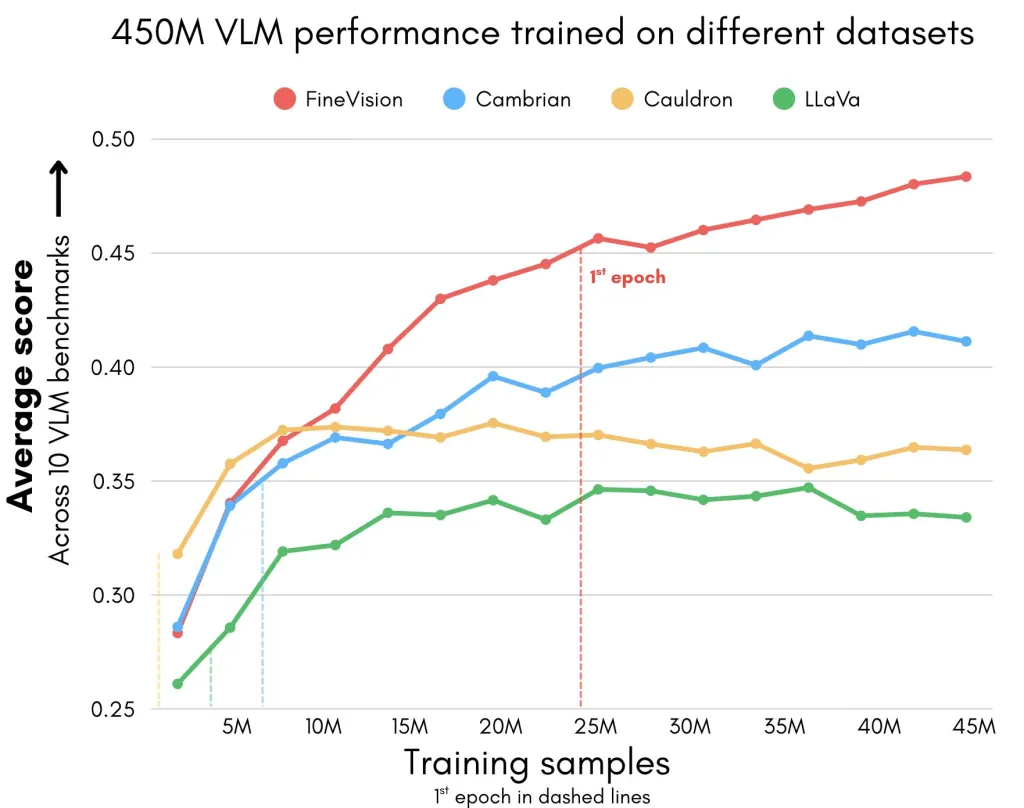
FineVision 在 11 个广泛使用的基准上表现优于其他替代方案,平均提升 20%。
-
FineVision 引入了 GUI 导航、指向和计数等新兴任务的数据,扩展了 VLM 的功能。
-
数据整理流程包括收集与增强、清洗和质量评级,确保数据的高质量。
-
FineVision 的污染率为 1%,显著低于其他数据集的 2-3%。
-
FineVision 完全开源,研究人员和开发者可以通过 Hugging Face Hub 访问。
-
FineVision 标志着开放多模态数据集的重大进步,为训练最先进的视觉语言模型奠定基础。
延伸解读
FineVision 的数据质量优势
FineVision 数据集的污染率仅为 1%,远低于其他数据集的 2-3%。这一显著优势意味着研究人员在使用 FineVision 进行模型训练时,可以更有效地减少数据泄漏的风险,从而提高模型的可靠性和准确性。
新兴任务的扩展
FineVision 不仅包含传统的视觉问答(VQA)数据,还引入了 GUI 导航、指向和计数等新兴任务的数据。这种多样化的任务设置为视觉语言模型的应用提供了更广泛的可能性,推动了相关领域的研究进展。
开源的影响
FineVision 完全开源,研究人员和开发者可以通过 Hugging Face Hub 轻松访问。这种开放性不仅促进了学术界的合作与创新,也降低了使用高质量数据集的门槛,推动了视觉语言模型的普及和发展。
延伸问答
FineVision 数据集的规模和内容是什么?
FineVision 数据集包含1730万张图片和近100亿个答案标记,是规模最大、结构最完善的公开 VLM 训练数据集之一。
FineVision 如何提升视觉语言模型的训练质量?
FineVision 经过严格过滤和系统评级,减少数据泄漏,确保数据的高质量,从而提升视觉语言模型的训练质量。
FineVision 在基准测试中的表现如何?
FineVision 在11个广泛使用的基准上表现优于其他替代方案,平均提升20%。
FineVision 数据集支持哪些新兴任务?
FineVision 引入了用于 GUI 导航、指向和计数等新兴任务的数据,扩展了 VLM 的功能。
FineVision 的污染率是多少?
FineVision 的污染率为1%,显著低于其他数据集的2-3%。
如何访问 FineVision 数据集?
FineVision 完全开源,研究人员和开发者可以通过 Hugging Face Hub 访问。
