ChartNet是由麻省理工学院等机构开发的高质量多模态数据集,包含150万个图表样本,涵盖24种图表类型,旨在提升AI对图表的理解能力。该数据集支持图表重建、数据提取和摘要生成等任务。研究表明,微调模型在ChartNet上表现优于现有大型模型,推动了视觉语言模型在图表理解领域的进步。
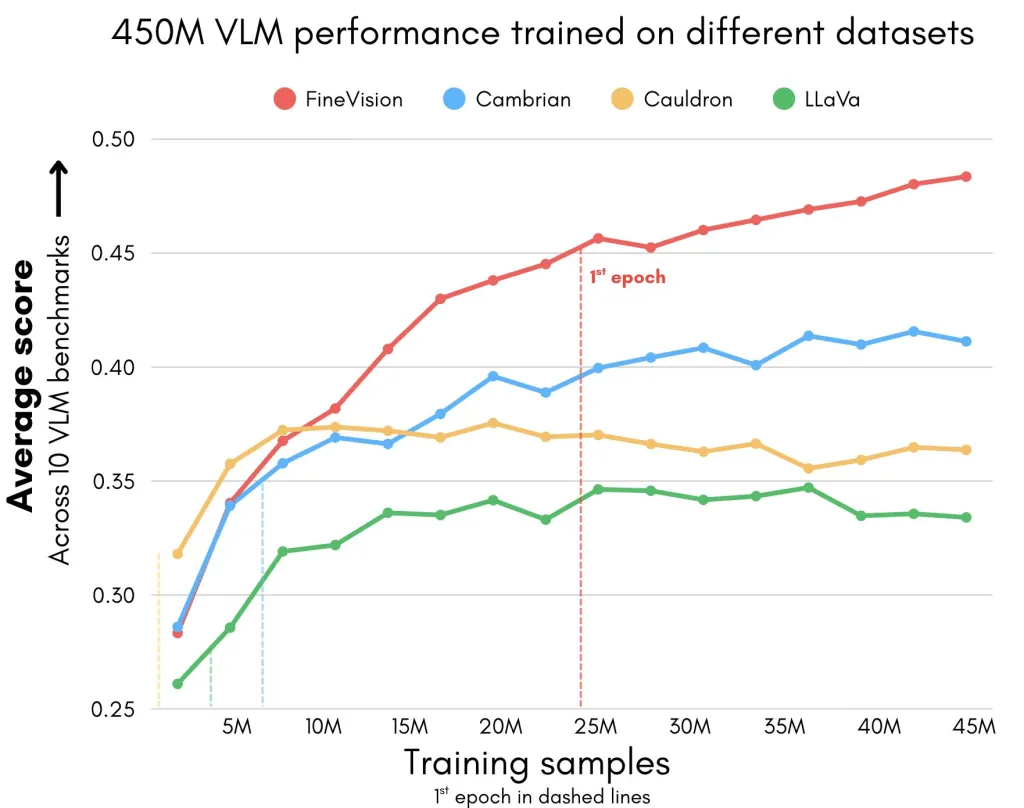
Hugging Face 发布了 FineVision,一个包含 1730 万张图片和近 100 亿个答案标记的开放多模态数据集。该数据集经过严格筛选和系统评级,提升了视觉语言模型的训练质量,支持多种新兴任务,减少数据泄漏,推动研究的可重复性和可访问性。
本研究提出了一种基于RGB-事件的行人属性识别方法,并推出了首个大规模多模态数据集EventPAR,涵盖50个属性和六种情感。通过重训练主流模型并引入RWKV框架,取得了先进的识别性能,为未来研究提供了数据和算法基准。
本研究提出了一个农作物疾病诊断的多模态数据集(CDDM),包含137,000张图像和100万个问答对,结合视觉与文本数据,提升农业专家的诊断能力。通过低秩适应微调策略,显著提高了多模态模型在疾病诊断中的表现。
本研究探讨了语言模型在理解元音发音机制方面的不足,尤其是舌位与元音之间的关系。通过多模态数据集发现,模型在有示例时能够理解这些关系,但在没有示例时则表现出困难。
本研究提出了一种多模态数据集,旨在展示现实生活中的规范与非规范行为,以帮助儿童学习社会原则。该数据集可用于训练遵循社会规范的人工智能系统,具有重要的应用价值。
本研究提出了Motion-X++,一个大规模多模态3D全身人体运动数据集,解决了现有数据集中面部表情、手势和细粒度姿态描述不足的问题。该数据集包含1915万个3D全身姿态注释,提升了自然运动生成的准确性和应用潜力。
大规模语言模型推动了人工智能,特别是在遥感领域。研究构建了高质量的遥感图像字幕数据集RSICap,促进了视觉语言模型的训练与评估。SkyScript和EarthGPT等模型通过多模态数据集提升了遥感任务的性能,解决了语言偏见和模型局限性问题。
本研究提出了人类场景视觉语言模型(HumanVLM),旨在解决现有模型在特定人类场景理解中的不足。通过构建大规模多模态数据集,HumanVLM在多模态任务中表现优异,尤其在人相关任务上显著超越同类模型,推动了相关领域的研究进展。
本研究提出了一种快速构建日语多模态数据集的方法,以解决日语在视觉语言模型开发中的资源不足问题。实验结果表明,使用本土数据集训练的模型性能优于依赖机器翻译的模型。
本研究针对罗马尼亚语表情包数据不足的问题,创建了一个多模态表情包数据集,并进行了详细注释。实验表明,AI工具在处理表情包方面仍需改进,强调了该数据集的实用性和未来研究的重要性。
该研究探讨了利用自监督学习和IMU传感器捕捉人类与狗的视角视频,以识别自传活动。提出了多模态数据集和基于递归神经网络的方法,旨在提高物体操纵行为的预测精度。此外,研究介绍了EgoGen合成数据生成器,以提供真实数据,解决增强现实中的人类运动模拟挑战。
该研究提出了SemArt多模态数据集,旨在实现语义艺术理解和Text2Art挑战。通过计算机视觉技术,优化了艺术作品的分类和检测,并探讨了知识图谱在图像字幕生成中的应用。研究还提出了多模态知识图谱和机器学习系统,以量化分析艺术作品。最新的LVLMs在艺术品解释生成任务中展现了潜力,但仍面临知识整合的挑战。
本研究提出了一种新方法,解决传统RGB相机在捕捉微小面部动作时的不足。通过创建多模态数据集FACEMORPHIC,并利用跨模态监督技术,实现了有效的神经形态面部分析,成功弥补了不同数据域之间的差距。
本研究聚焦于遥感图像的开放集语义分割技术,提出了一种新方法并进行评估,结果显示其在多个数据集上具有竞争力的准确性。同时,构建了大规模多模态数据集,推动开放词汇检测和分割的进展,提出新的任务和框架,以提升遥感领域的视觉-语言模型性能。
本研究提出了一种新方法,通过脑电图(EEG)信号解码和重建图像,结合深度学习提高模型可解释性。实验结果表明,该方法在图像分类和重建方面表现优异,准确率达到82%。此外,研究建立了大规模多模态数据集EIT-1M,支持视觉和文本刺激的EEG识别,推动脑-计算机界面的应用发展。
本研究探讨了现代神经模型在自动生成生物医学证据摘要中的效果。结果表明,生成的摘要流畅但准确性不一。通过优化输入片段和强调高质量试验,摘要的准确性有所提升。此外,研究提出了一个多模态医疗问题摘要数据集,结合图像辅助生成更详细的医疗摘要,以改善医疗决策和患者理解。
本研究探讨了在3D中性氢21厘米谱线数据中寻找和屏蔽射电源的最佳方法。通过比较传统源查找方法与深度学习技术,发现SoFiA与随机森林结合效果最佳。同时,提出了RADiff模型以生成合成图像,解决数据集类别失衡问题,并展示了高准确率的分类方法。新开发的多模态数据集支持自动检测多组件射电星系及其红外主机,为未来研究提供了重要资源。
本文介绍了多个用于车路协同自动驾驶的多模态数据集和算法,包括DAIR-V2X、TUMTraf-V2X和V2V4Real,旨在提升车辆与基础设施的协作感知能力。研究强调数据共享的重要性,并提出新的模型和检测器,以提高三维物体检测的准确性和效率。这些数据集和模型为自动驾驶技术的发展提供了重要支持。
华盛顿大学、Salesforce Research和斯坦福大学等机构联合构建了规模空前的开源多模态数据集MINT-1T,包含一万亿文本token和三十亿张图像。该数据集经历了多个步骤,包括数据收集、过滤和去重。实验结果显示,在MINT-1T数据集上训练的模型在多个基准任务上表现优于之前的数据集。这个超大规模的开源多模态数据集有望成为多模态大模型的起点。
完成下面两步后,将自动完成登录并继续当前操作。