
突破零样本TTS音色克隆上限:LongCat-AudioDiT 的声音克隆艺术
内容提要
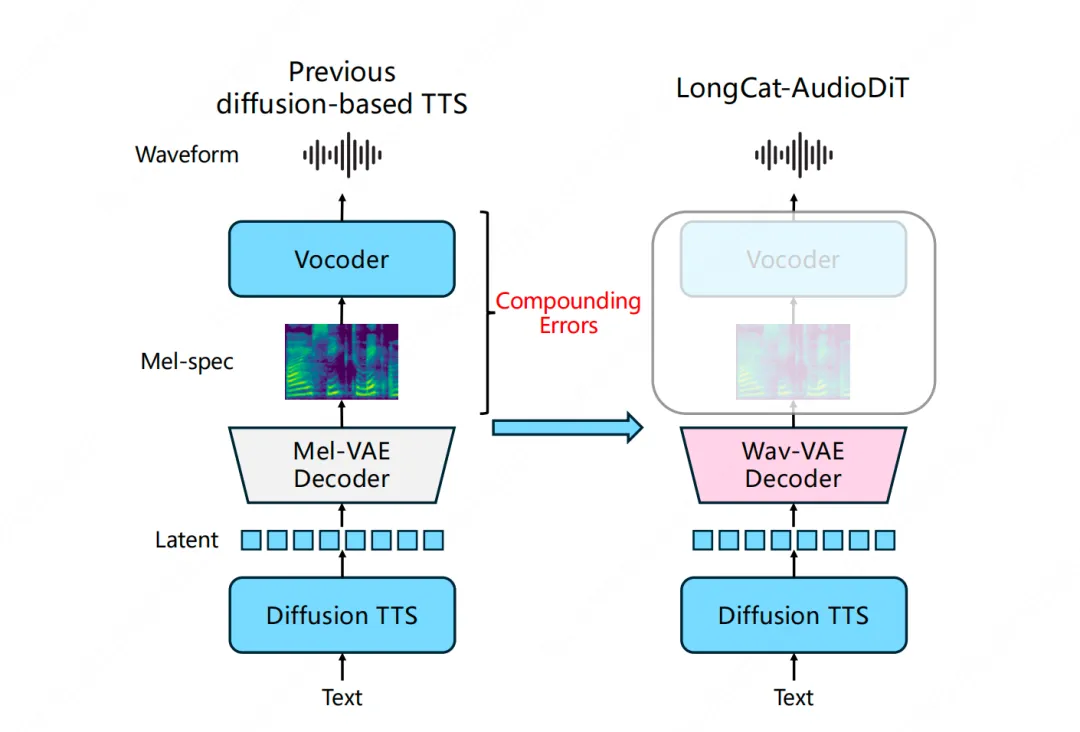
音频生成技术正向端到端生成演进。美团LongCat团队推出LongCat-AudioDiT,直接在波形潜空间进行文本转语音,避免信息损失。该模型在Seed基准测试中表现优异,取得了SOTA的说话人相似度和可懂度,展现出强大的零样本语音克隆能力。
关键要点
-
音频生成技术正在向端到端生成范式演进,避免信息损失。
-
美团LongCat团队推出LongCat-AudioDiT,直接在波形潜空间进行文本转语音。
-
LongCat-AudioDiT在Seed基准测试中表现优异,取得SOTA的说话人相似度和可懂度。
-
模型抛弃梅尔谱等中间表示,减少数据转换的级联误差。
-
Wav-VAE作为压缩器,压缩比超过2000倍,保持音频质量。
-
扩散Transformer在隐空间中学习文本到声音的映射,提升生成语音的可懂度。
-
双重约束对齐修复训练-推理不匹配问题,确保生成语音的稳定性。
-
自适应投影引导缓解CFG过饱和问题,提升生成语音的自然度。
-
VAE重建质量与语音生成效果并不成正比,需优化潜空间维度。
-
LongCat-AudioDiT在零样本语音克隆任务中展现出强大的竞争力。
延伸解读
音频生成技术的演进
LongCat-AudioDiT的推出标志着音频生成技术从传统的级联架构向更高效的端到端生成范式转变。这种转变不仅减少了信息损失,还提升了生成语音的质量,尤其在零样本语音克隆任务中展现出强大的能力。
模型性能与行业比较
LongCat-AudioDiT在Seed基准测试中表现优异,超越了多款知名模型,显示出其在说话人相似度和可懂度上的竞争力。这一成果表明,新的生成架构能够在不依赖高质量人工标注数据的情况下,仍然实现卓越的性能。
推理机制的创新
LongCat-AudioDiT在推理过程中引入了双重约束对齐和自适应投影引导等创新机制,显著提升了生成语音的自然度和稳定性。这些技术突破解决了传统模型中存在的训练与推理不匹配问题,确保了生成结果的高质量。
延伸问答
LongCat-AudioDiT的主要创新是什么?
LongCat-AudioDiT的主要创新是直接在波形潜空间进行文本转语音,避免了中间表示带来的信息损失。
LongCat-AudioDiT在Seed基准测试中的表现如何?
LongCat-AudioDiT在Seed基准测试中取得了SOTA的说话人相似度和可懂度,表现优异。
Wav-VAE在LongCat-AudioDiT中的作用是什么?
Wav-VAE作为压缩器,将原始波形压缩为紧凑的隐向量,保持音频质量并提高训练稳定性。
自适应投影引导(APG)如何改善语音生成质量?
APG通过精准筛选引导信号,抑制劣化部分,从而提升生成语音的自然度和音质。
LongCat-AudioDiT如何解决训练-推理不匹配问题?
LongCat-AudioDiT通过双重约束对齐机制,确保提示区域的隐变量与训练分布对齐,从而修复不匹配问题。
LongCat-AudioDiT的零样本语音克隆能力如何?
LongCat-AudioDiT在零样本语音克隆任务中展现出强大的竞争力,取得了高相似度和可懂度。
