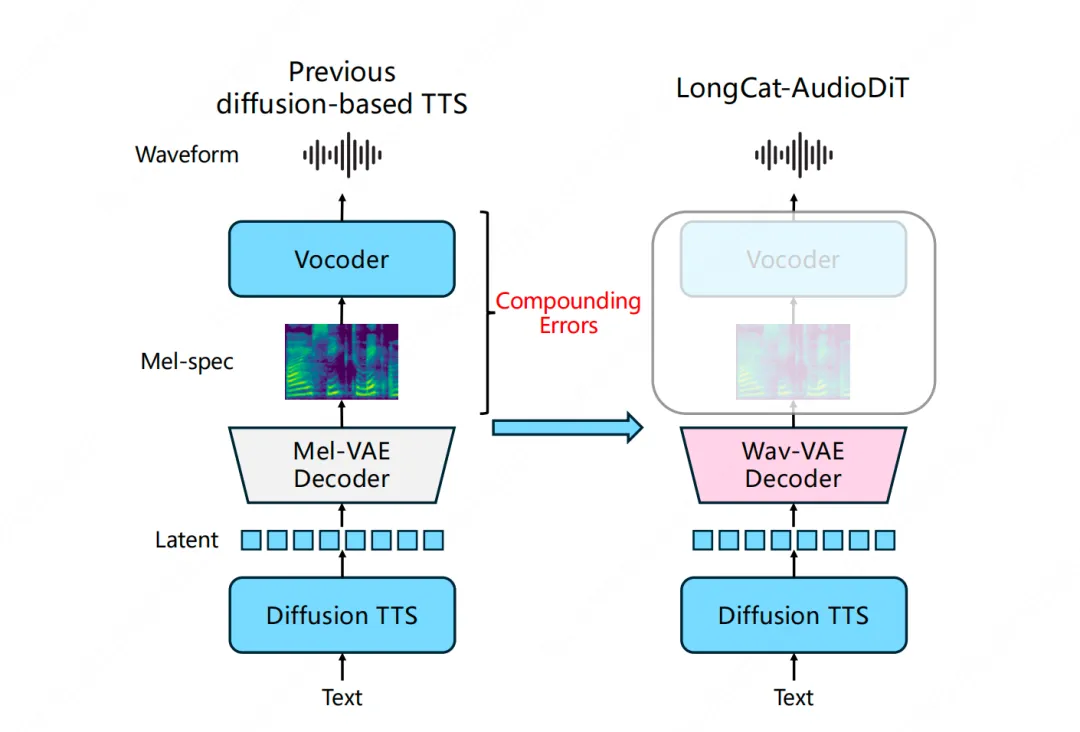
音频生成技术正向端到端生成演进。美团LongCat团队推出LongCat-AudioDiT,直接在波形潜空间进行文本转语音,避免信息损失。该模型在Seed基准测试中表现优异,取得了SOTA的说话人相似度和可懂度,展现出强大的零样本语音克隆能力。
本研究提出了一种新方法,解决低资源语言在语音合成中的数据不足和复杂性问题。该方法结合数据优化框架和先进声学模型,支持零样本语音克隆,提升了在金融、医疗等领域的应用表现。
本文探讨了结合零样本语音克隆与多语言低资源语音合成的方法。通过元学习和TTS编码器的改进,系统能够在仅5分钟训练数据下学习新语言,并保留说话者声音的推断能力。研究表明,该模型在多语言语音合成中表现自然且准确,显著提高了低资源语言的TTS系统开发效率。
本文介绍了一种结合大型语言模型(LLMs)和适配器的上下文化语音识别方法,显著提升了性能。研究探讨了多语言语音合成、零样本语音克隆及语音生成模型SpeechX的应用,展示了其在多种任务中优于传统模型的效果,并通过改进训练方法和数据使用,实现了高质量的个性化语音合成。
本文探讨了零样本语音克隆与多语言低资源语音合成的结合,展示了如何在仅有5分钟训练数据的情况下学习新语言,并保持对不同说话者声音的推断能力。研究分析了自动演讲者验证模型的性能受音频质量和参与者特征的影响,并提出了改进数据收集的建议。此外,研究展示了多语言语音合成和转换在自动语音识别系统中的应用,强调了使用少量真实说话者数据的有效性。
完成下面两步后,将自动完成登录并继续当前操作。