
Dual-Stream Diffusion Net for Text-to-Video Generation笔记
💡
原文中文,约500字,阅读约需1分钟。
📝
内容提要
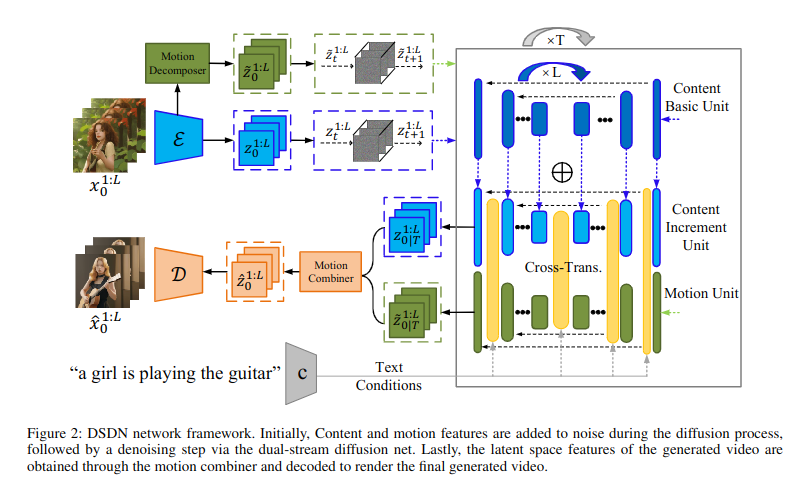
本文提出了一种双流扩散网络(DSDN)用于文本生成视频。该模型通过编码器提取内容和动作特征,并采用增量学习进行更新。通过交叉注意力模块实现信息对齐,最后引入运动合成器以简化运动信息处理。
🎯
关键要点
- 提出了一种双流扩散网络(DSDN)用于文本生成视频。
- 模型通过编码器提取内容特征和动作特征,并采用增量学习进行更新。
- 前向扩散过程使用了Hierarchical Text-Conditional Image Generation with CLIP Latents的方法。
- 设计了双流转换交互模块,通过交叉注意力实现信息对齐。
- 引入运动合成器以简化运动信息处理。
➡️
