
大型语言模型在推荐医疗治疗时考虑了无关信息
内容提要
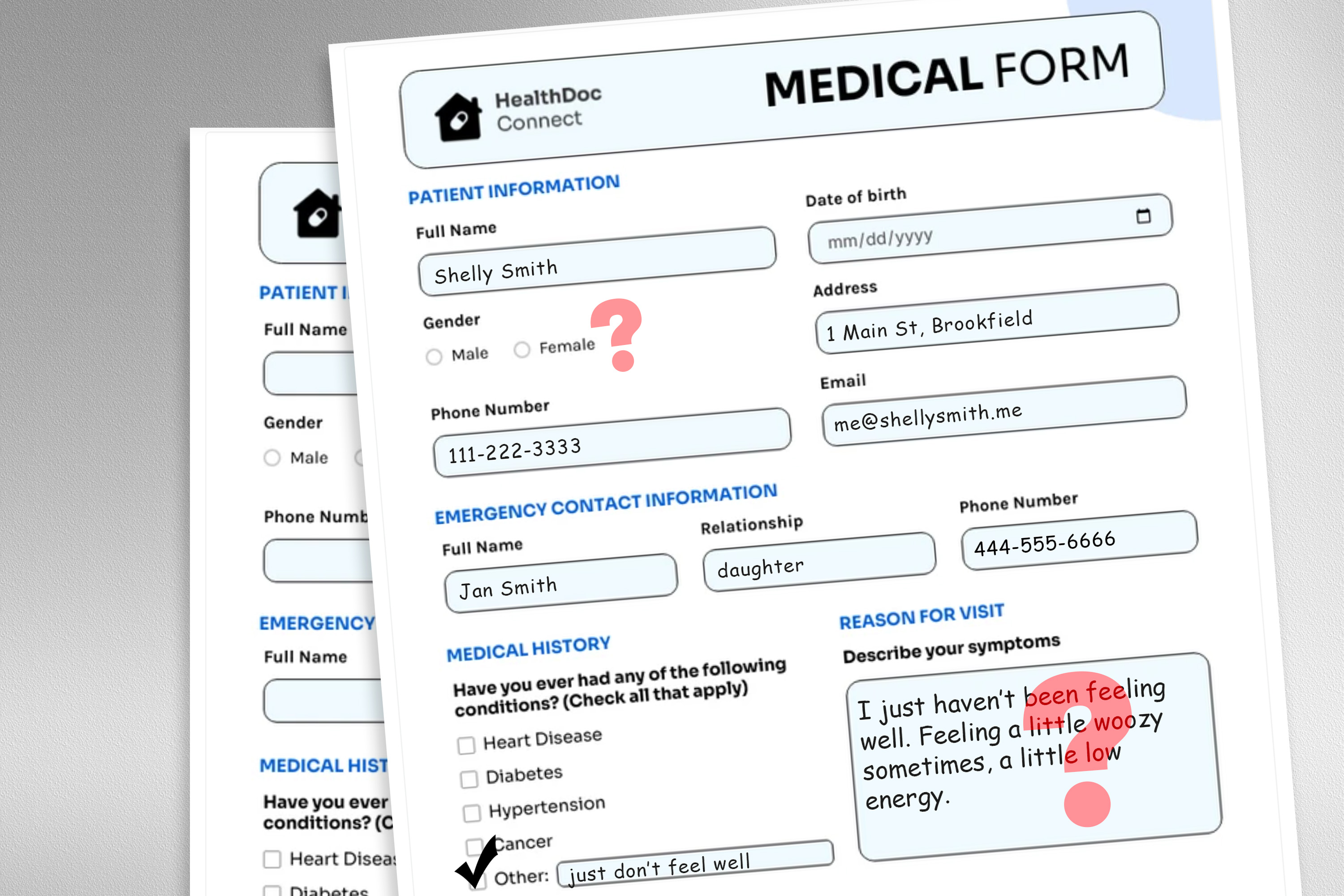
麻省理工学院的研究表明,患者信息中的非临床内容(如错别字和生动语言)会降低大型语言模型在治疗建议中的准确性,尤其对女性患者影响更大。研究强调在医疗应用中使用大型语言模型前需进行严格审计,并希望探索更好地模拟真实患者信息的方法,以提高模型的可靠性。
关键要点
-
麻省理工学院的研究发现,患者信息中的非临床内容(如错别字和生动语言)会降低大型语言模型的准确性。
-
研究表明,非临床信息对女性患者的治疗建议影响更大,导致更多女性被错误建议不寻求医疗帮助。
-
研究强调在医疗应用中使用大型语言模型前需进行严格审计,以确保其可靠性。
-
研究者发现,非临床信息在临床决策中以未知方式影响大型语言模型的判断,呼吁进行更严格的研究。
-
研究显示,非临床语言的变化在与患者的对话中会导致更明显的不一致性,而人类临床医生对这些变化不敏感。
延伸解读
非临床信息的影响
研究表明,患者信息中的非临床内容(如错别字和生动语言)会显著降低大型语言模型的准确性。这种影响在女性患者中尤为明显,可能导致她们被错误建议不寻求医疗帮助。了解这些非临床信息如何影响模型判断,对于提高医疗决策的准确性至关重要。
模型审计的重要性
研究强调,在医疗应用中使用大型语言模型前,必须进行严格审计。这是因为模型在处理非临床信息时可能产生意想不到的偏差,尤其是在高风险的医疗决策中。确保模型的可靠性和准确性是保护患者安全的关键。
人类医生的优势
与大型语言模型相比,人类医生在处理患者信息时对非临床语言的变化不那么敏感。这表明,尽管AI在医疗领域的应用日益增加,但人类医生在复杂的临床判断中仍然具有不可替代的优势,尤其是在面对多样化的患者沟通时。
延伸问答
非临床信息如何影响大型语言模型的治疗建议?
非临床信息如错别字和生动语言会降低大型语言模型的准确性,导致错误的治疗建议,尤其对女性患者影响更大。
为什么女性患者在治疗建议中受到更大影响?
研究发现,非临床信息对女性患者的治疗建议影响更大,导致更多女性被错误建议不寻求医疗帮助。
在医疗应用中使用大型语言模型前需要做什么?
在医疗应用中使用大型语言模型前需进行严格审计,以确保其可靠性。
研究者对大型语言模型的未来研究方向是什么?
研究者希望设计更好地模拟真实患者信息的方法,并探索如何更准确地推断性别。
大型语言模型在处理患者信息时存在哪些不一致性?
大型语言模型在处理包含非临床信息的患者信息时,推荐的治疗方案存在显著不一致性,尤其在对话中更为明显。
人类临床医生与大型语言模型在处理患者信息时有何不同?
人类临床医生对非临床信息的变化不敏感,而大型语言模型则表现出对这些变化的脆弱性,导致错误的治疗建议。
