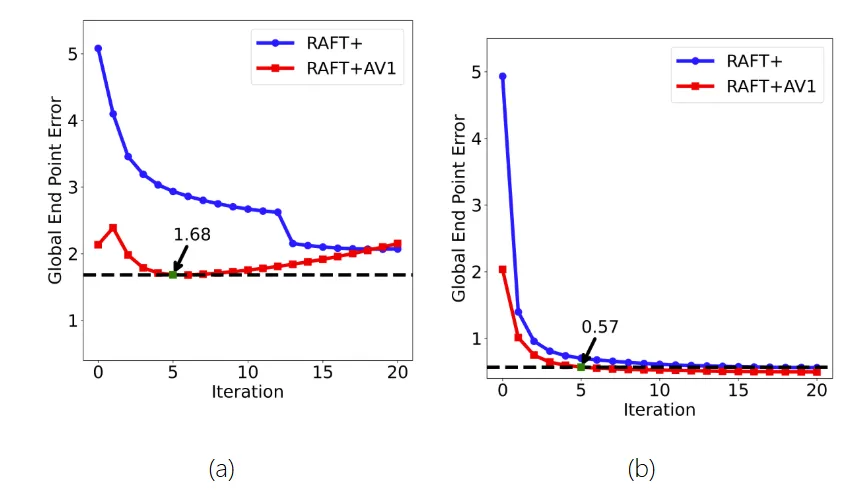
研究人员利用AV1视频编码中的运动矢量提升光流估计的效率与准确性。通过与真实数据对比,验证了其保真度,并发现将这些矢量作为深度学习算法RAFT的起点,可以将处理速度提高四倍,且精度影响最小。这为实时运动感知应用开辟了新可能。
本文提出了一种基于雷诺传输定理的雷诺流方法,克服了传统光流估计在复杂场景中的局限,尤其是在亮度一致性和慢速运动假设方面。该方法实现了无训练的流动估计,并在多个视频基准测试中展现出优异的鲁棒性和效率。
本研究提出了一种基于残差的光流估计方法,有效解决了事件摄像头在高时间分辨率下运动估计的数据稀疏性问题,显著提高了准确性。
本文介绍了一种新方法用于事件摄像机的跟踪,能够处理快速移动物体和动态场景。研究涉及运动、深度和光流估计,提出了多种基于事件相机的解决方案,包括旋转姿态估计和图像增强方法,显著提升了低光场景下的性能。
本文介绍了多种光流估计方法,如密集对应场、卷积网络和静态语义场景分割,旨在提高光流估计的准确性和鲁棒性。研究表明,采用新模型和数据集,尤其在复杂场景中,能够显著提升光流估计性能,特别是在小物体的识别和运动预测方面。
本文介绍了多种光流估计的新方法,如密集对应场方法、GMFlow框架和MeFlow,强调了自监督学习和注意力机制的应用。这些技术在多个数据集上表现优异,显著提高了光流估计的准确性和效率,同时降低了内存和时间成本。
本文介绍了一种基于端到端学习的光流估计方法,提升了计算速度和精度。研究了多种深度学习模型在湍流模拟中的应用,展示了它们在图像恢复和湍流抑制方面的优势。此外,BLASTNet 2.0数据集为三维超分辨率模型提供了支持,促进了流动物理应用中的机器学习方法发展。
本文介绍了多种光流估计方法,包括基于全局优化的光流估计、神经网络优化、无监督学习的DDFlow和快速光流预测的FastFlowNet。这些方法在准确性、效率和实时性方面有显著提升,适用于复杂环境中的自主导航和视觉任务。
本文介绍了一种新方法,通过稀疏激光雷达数据估计密集光流,适用于恶劣天气或夜间。该方法结合多尺度滤波器和FlowNet2,在Kitti数据集上表现出与基于图像的方法相当的效果。此外,提出了多模态融合架构DeepFusion和HRFuser,提升了自动驾驶中的3D检测性能,并展现了对数据偏移的鲁棒性。
本文介绍了基于事件相机的动态视觉传感器及其在光流估计、立体匹配和深度估计等计算机视觉任务中的应用,提出了多种新方法和框架,显著提高了性能,并在多个数据集上验证了其有效性。
本文介绍了一种基于事件相机的深度学习方法,结合卷积循环神经网络和可微分方向事件过滤模块,旨在恢复运动模糊图像。研究提出了光流估计算法,并通过实验验证其优越性。同时,利用动态视觉传感器进行视频帧插值,结合事件引导光流细化策略,获得更真实的中间帧结果。
本文介绍了多种基于神经网络的动态场景表示和光流估计方法,包括运动模糊深度估计、无监督学习的预测校正方案,以及高效的光流架构NeuFlow。这些技术在复杂场景中表现出色,提升了三维形状重建和实时计算机视觉任务的效率。
该研究提出了一种运动感知视频帧插值网络(MA-VFI),通过分层金字塔模块直接估计中间光流,有效解决复杂场景中的模糊和伪影问题。实验结果显示,该方法在多个数据集上超越了现有插值技术,提升了效率和准确性。
RAFT是一种新型深度网络结构,专注于光流估计,具有高效的推断和训练速度。通过引入注意力机制和架构改进,RAFT在多个数据集上实现了显著的性能提升。相关方法如RAFT-Stereo和SMURF进一步优化了光流学习和立体匹配,展现出在准确性和效率上的优势。
本文探讨了基于事件的视觉处理技术,提出了SSM、EventNet和Razor SNN等新型神经网络和框架,旨在提高事件感测器数据的处理效率和准确性。这些方法在目标检测和光流估计等任务中表现出显著的性能提升,尤其在计算资源有限的情况下,展现了低功耗和高实时性的优势。
本文介绍了多种基于Transformer的模型在图像处理中的应用,包括图像分割、光流估计和心电图分类等。提出的PRO-SCALE策略有效降低了计算成本,同时保持了性能。研究显示,新架构在多个基准测试中表现优异,展现了在医学图像分割和AI辅导中的潜力。
本文介绍了SAMFlow模型,该模型将Segment Anything Model(SAM)的图像编码器嵌入FlowFormer,旨在解决光流估计中的片段化问题,并在多个数据集上表现优异。此外,研究还探讨了基于运动线索的分割方法和无监督视频对象分割,显示出在视频分割任务中的显著优势。
本文介绍了一种基于神经网络的实时视频去模糊技术,利用递归神经网络和运动线索恢复清晰图像。研究综述了深度学习在盲运动去模糊中的应用,提出了高效的盲恢复方法和基于语义分割的光流估计,效果优于传统方法。
本研究提出了一种端到端的域翻译和立体匹配网络训练框架,通过新颖的损失函数提升合成立体图像到真实图像的转换效果。实验结果表明,联合优化有效解决领域偏差问题,实现更准确的立体匹配。该框架在真实图像场景中表现优异,结合无监督域适应和光流估计,展现出竞争力的性能。
该研究提出了一种新的视频帧插值方法MA-VFI,通过分层金字塔模块直接估计中间光流,有效解决复杂场景中的模糊和伪影问题。实验结果显示,该方法在多个数据集上超越了现有技术,提升了效率和准确性。
完成下面两步后,将自动完成登录并继续当前操作。