本文探讨深度学习理论中网络输出的分析方法,将随机初始化的多层感知机视为输入的哈密顿量,揭示了能量景观的性质,特别是无限宽度下近全局最小值的结构,并分析了不同激活函数对能量景观的影响。
本文提出了一种基于代数的机器学习新基础,通过将任务目标和数据编码为代数公理,实现模型的泛化。实验结果表明,该方法在标准数据集上的性能与优化后的多层感知机相当,并可扩展至形式问题的求解。
本研究探讨了离线强化学习中的目标条件监督学习,提出了递归跳跃规划(RSP)方法,验证了浅层多层感知机在长期轨迹动态捕捉中的有效性,显著降低了序列建模误差。
本研究提出了一种通过单次前向传播提升贝叶斯深度学习预测效率的方法,利用激活函数的局部线性化和线性层的高斯近似,成功应用于多层感知机和变压器模型的回归与分类任务。
本研究提出了一种新方法,将基于注意力的多变量时间序列预测模型简化为多层感知机(MLP),通过前馈、跳跃连接和层归一化操作实现。结果显示,该方法显著降低了计算量,同时保持了可接受的性能,展示了其高效性和可行性。
科尔莫戈洛夫-阿诺德网络(KANs)作为多层感知机(MLPs)的替代方案,展现出更高的准确性和可解释性。研究表明,KAN在图像识别和时间序列数据处理上表现优异,尤其在鲁棒性方面具有潜力。与传统模型相比,KAN在参数效率和性能上均有显著提升,为深度学习模型的优化提供了新思路。
本文提出了一种名为BlockPruner的无训练结构化修剪方法,能够有效识别和去除冗余的多头注意力和多层感知机块。研究表明,在移除多层之前,模型性能仅轻微下降,剪枝显著降低了内存和计算成本。通过对Transformer模块的冗余性分析,发现可以安全剪枝大量Attention层,从而提升性能。最终,该方法在多个数据集上表现优于现有技术。
本文介绍了一种基于消息传递的链接预测模型(MPLP),通过准正交向量捕捉结构特征,优化图神经网络性能。研究表明,信息传递神经网络在节点分类任务中表现优越,提出的多层感知机模型在缺乏邻接信息时仍具竞争力。新框架Hypergraph-MLP在超图节点分类中也展现了良好性能。
本文提出了一种结合多层感知机和循环神经网络的非线性Granger因果分析方法,适用于脑科学和基因组学等领域。该方法通过自动裁剪滞后项和处理长程依赖关系,优于现有技术,能够有效推断因果关系及其符号变化,具有良好的可解释性和性能。
本文研究了多层感知机(MLP)在表格数据集上的优化,利用13种正则化技术显著提升性能。同时探讨了大型语言模型在小样本学习中的应用,提出了FealtLLM框架以生成高质量特征,提高预测准确性。此外,AutoGluon-Tabular框架通过组合模型实现高效训练,表现优于其他AutoML工具。研究表明,传统机器学习在某些任务上仍优于深度学习方法。
本文探讨了相机姿态自编码器(PAEs)在多层感知机神经网络训练中的应用,提出了PoseMap特征和相对位移回归方法,显著提高了室内外场景的定位精度。结合绝对姿态回归和特征匹配,解决了光度变形问题,并提出了无需三维地图的重定位技术,推动了视觉定位领域的发展。
本研究提出了一种高效的三维道路重建方法RoMe,该方法通过多层感知机分解道路,保留细节并引入新路点抽样方法。实验结果表明,RoMe在公共数据集上表现出高效性和准确性。
本文研究了线性模型在时间序列预测中的能力,并提出了基于多层感知机的模型TSMixer。TSMixer在学术基准测试和真实世界的M5基准测试中表现出良好性能,强调了利用交叉变量和辅助信息提高时间序列预测性能的重要性。预计TSMixer的设计将为基于深度学习的时间序列预测带来新的视野。
本文提出了一种基于MLP网络的嵌入式特征选择方法,可用于组特征或传感器选择问题。该方法可控制冗余级别,并通过组套索惩罚推广为特征选择机制。实验结果表明,该方法在特征选择和组特征选择方面具有良好性能。
本文介绍了一种带有线性激活函数和批归一化的多层感知机模型,证明了其正向信号传播特性的精确表征。同时,提出了一种激活函数塑形方案,能够在某些非线性激活函数下实现类似的特性。在线性独立的输入样本情况下,该模型能够渐近地保持梯度有界的特性。
本文介绍了一种基于多层感知机的图神经网络模型(Graph-MLP),利用图结构的监督信号,无需信息传递模块,使用邻域对比损失(NContrast)进行分类任务。研究表明,该模型即使在没有邻接信息的情况下也能达到最先进模型相媲美的性能。
本文提出了一个简单的多模式时空数据建模框架,通过设计一个跨模式空间关系学习组件来自适应地建立多个模式之间的连接,并使用多层感知机来捕捉时态依赖和通道相关性。实验证明该模型在三个真实数据集上始终优于基准模型,具有更低的空间和时间复杂度,为时空数据建模开辟了一种有前景的方向,同时也验证了跨模式空间关系学习模块的一般化能力。
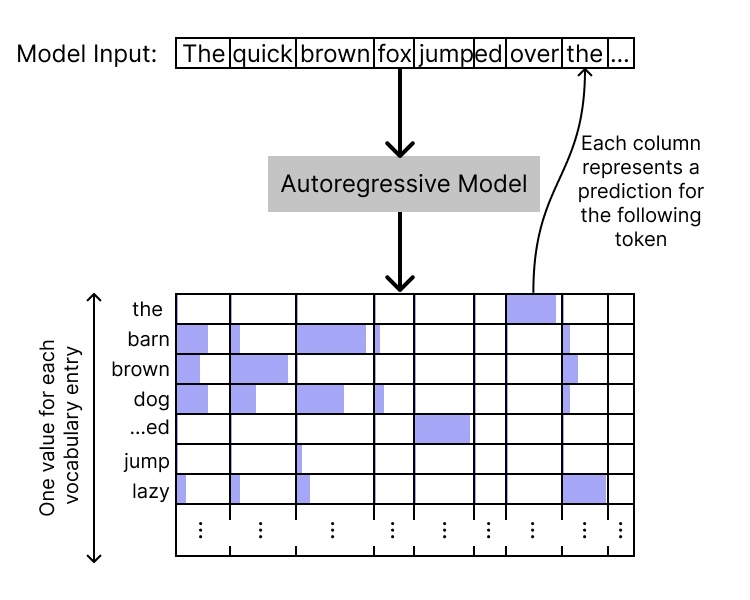
自2017年提出的Transformer模型架构在深度学习领域迅速崛起,广泛应用于文本、音频和视频等多个领域。本文介绍了Transformer的基本结构和工作原理,重点讨论了模型的可解释性,详细阐述了模型的层次结构、注意力机制和多层感知机(MLP)层的实现,以帮助软件工程师理解Transformer的内部运作。
完成下面两步后,将自动完成登录并继续当前操作。