
软件工程师的Transformer
内容提要
自2017年提出的Transformer模型架构在深度学习领域迅速崛起,广泛应用于文本、音频和视频等多个领域。本文介绍了Transformer的基本结构和工作原理,重点讨论了模型的可解释性,详细阐述了模型的层次结构、注意力机制和多层感知机(MLP)层的实现,以帮助软件工程师理解Transformer的内部运作。
关键要点
-
自2017年提出的Transformer模型架构在深度学习领域迅速崛起,广泛应用于文本、音频和视频等多个领域。
-
Transformer模型最初用于机器翻译,现已成为多种领域的首选工具。
-
Transformer的核心内部架构是由多个相同结构的层堆叠而成,每层接收前一层的隐藏状态并进行计算。
-
Transformer模型的主要组成部分包括嵌入层、残差块和解嵌入层。
-
注意力机制是Transformer的关键,使用多头注意力来处理不同的子空间。
-
多层感知机(MLP)层在Transformer中负责对状态进行非线性变换。
-
Transformer的可解释性是当前研究的重点,旨在理解模型内部的算法和执行过程。
-
模型的层次结构、注意力机制和多层感知机的实现对于软件工程师理解Transformer的内部运作至关重要。
延伸解读
Transformer的多领域应用
自2017年提出以来,Transformer模型已广泛应用于文本、音频和视频等多个领域。其最初用于机器翻译,但随着技术的发展,现已成为自然语言处理、图像生成等多种任务的首选工具。了解其多领域应用有助于软件工程师在不同项目中选择合适的模型架构。
可解释性的重要性
Transformer模型的可解释性是当前研究的重点,尤其是在理解模型内部算法和执行过程方面。软件工程师在使用这些模型时,需关注其可解释性,以便更好地调试和优化模型性能。掌握可解释性的方法将有助于提升模型的透明度和信任度。
注意力机制的核心作用
注意力机制是Transformer的关键组成部分,能够有效处理不同子空间的信息。理解多头注意力的工作原理对于软件工程师来说至关重要,因为它直接影响模型的性能和输出质量。掌握这一机制将有助于在实际应用中更好地调整和优化模型。
延伸问答
Transformer模型的基本结构是什么?
Transformer模型由多个相同结构的层堆叠而成,每层包括嵌入层、残差块和解嵌入层。
Transformer模型的注意力机制是如何工作的?
Transformer使用多头注意力机制,通过多个注意力头处理不同的子空间,计算每个位置的注意力分数。
Transformer模型的可解释性研究的重点是什么?
可解释性研究旨在理解Transformer模型内部的算法和执行过程,以便更好地预测模型的行为。
Transformer模型的多层感知机(MLP)层的作用是什么?
MLP层负责对状态进行非线性变换,增强模型的表达能力。
Transformer模型最初是为哪个任务设计的?
Transformer模型最初是为机器翻译任务设计的。
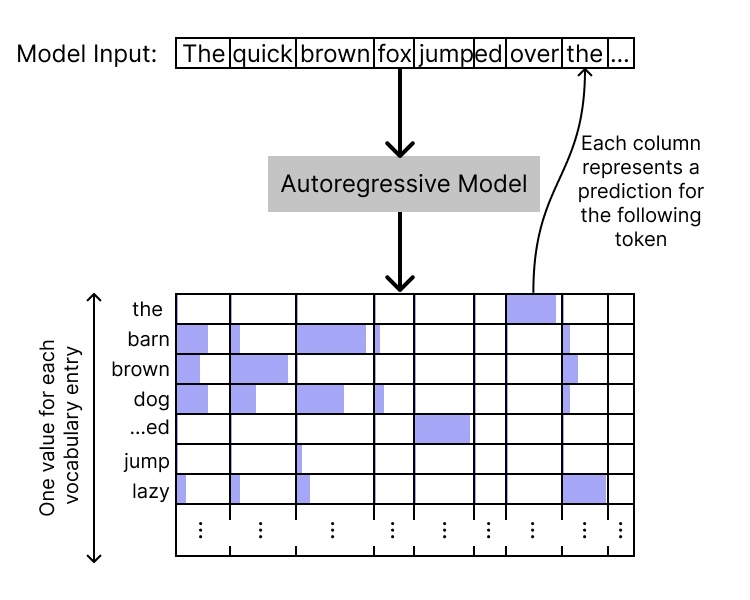
如何使用Transformer生成文本?
Transformer通过接收文本序列并输出相同长度的logits,表示下一个token的预测,从而生成文本。
