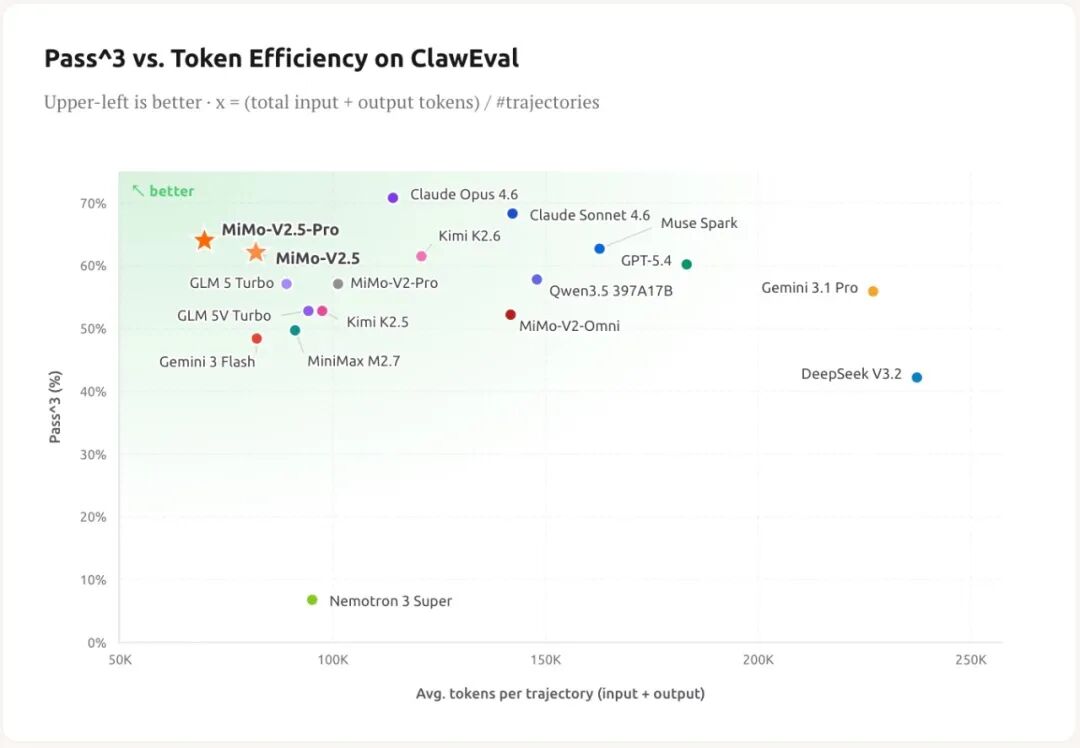
小米发布了MiMo-V2.5系列模型,包括V2.5和V2.5-Pro,具备更强的推理能力和指令理解。V2.5-Pro在复杂任务中表现优异,能够独立完成高质量项目,如用Rust实现SysY编译器,耗时仅4.3小时。V2.5支持多模态感知,提升Token效率,适用于大多数通用场景,且即将开源,用户可享受优化的Token计划。
阿里巴巴的Qwen 3.6 Plus已在Vercel AI Gateway上线,增强了编码能力和多模态感知,支持更复杂的任务。使用时需在AI SDK中设置为qwen/qwen3.6-plus。
AiMOGA奇瑞墨甲机器人在印尼车展亮相,凭借多模态感知和大模型技术,能够流利介绍奇瑞车型并主动识别客户推荐车型。首批220台机器人将于2025年4月交付多个市场,提升多语言服务能力。
联汇科技推出全球首个万物具身智能体平台OmAgent,旨在将AI智能体从数字空间引入物理世界。该平台支持多模态感知,具备3D空间感知、时空记忆和智能决策能力,实现跨设备协同。用户可通过自然语言指令操作智能终端,提升人机协作效率,已在多个行业应用,推动智能化进程。
本研究提出CAFES框架,旨在提升自动作文评分的评估泛化性和多模态感知能力。通过协作多智能体的方式,显著提高了评分与人类判断的一致性,实验结果显示评分准确性提升了21%。
本研究提出了一种新颖的神经脑框架,旨在提升具身人工智能系统在真实世界中的交互能力。该框架通过整合多模态感知、认知能力和适应性记忆,增强了代理在动态环境中的反应能力,推动了具身智能的发展。
该研究系统总结了图形用户界面(GUI)代理的最新进展,特别关注基于强化学习的架构,以及多模态感知和自适应动作生成在复杂环境中的应用。
本研究开发了一种高强度抓取器,具备嵌入式多模态感知功能,能够产生110牛顿的抓取力。该抓取器通过优化感知驱动,提升了物体抓取的精准性和效率,为类人机器人在复杂环境中的应用提供了新方案。
本研究比较了不同版本的GPT模型在多模态感知中的表现,发现GPT-4和GPT-4o与人类评估一致性高,但在模拟感官体验方面存在显著差异。
本研究提出机器人基础模型应从单一自主决策者转变为互动多代理视角,以应对人机协作的复杂性。通过多模态感知和记忆反馈机制,提升机器人性能,实现更强大和个性化的互动。
本文研究了深度强化学习在社交导航中的应用,开发了尊重社交规范的机器人导航策略。通过多模态感知和大规模数据集,提升了机器人在拥挤环境中的自主导航能力。提出的社交机器人规划器(SRLM)结合大型语言模型和深度强化学习,优化了机器人与人类的互动,显著提高了导航性能。
该论文提出了一种自监督预训练框架,通过神经辐射场实现多模态感知表示学习,提升三维感知任务的可迁移性。研究展示了多种方法的优越性,特别是在少样本学习和三维对象检测方面。
本文提出了一种基于混合网络的面部动作单元检测方法,解决了面部表情解码中的空间表示、时间建模和AU相关性问题。研究还介绍了多模态感知跟踪器和基于融合的未剪辑视频动作定位方法,均在多个数据集上取得了显著的性能提升,证明了其在复杂条件下的鲁棒性。
本文研究了使用多模态感知学习社交机器人导航的有效性,并将单模态和多模态学习与一组经典导航方法进行对比,结果表明多模态学习具有明显优势。同时,进行了一个人体研究,探究了使用多模态感知进行学习如何影响感知到的社交合规性。研究开源代码供社区使用。
完成下面两步后,将自动完成登录并继续当前操作。