Google DeepMind 发布了新款多模态模型 Gemma 4 12B,参数为120亿,但在多项测试中表现接近260亿参数的模型。其无编码器架构显著降低了推理延迟和内存占用,支持音频输入,并可在普通笔记本上运行,降低了部署成本,为开发者提供了接近顶级性能的选择。
本文介绍了如何结合Amazon SageMaker AI与Qualcomm AI Hub,实现从云端训练到端侧NPU的端到端工作流。通过微调模型并在真实设备上进行编译与验证,整个过程可在约20分钟内完成,显著缩短了AI项目的上线时间。以手机人像分割为例,最终在Galaxy S24上实现了13.59毫秒的推理延迟,展示了该方案的高效性与实用性。
Tensor Fusion是一种针对GPU集群的虚拟化和资源池解决方案,旨在提升集群利用率和降低推理延迟。它支持动态GPU池、低延迟推理、自动扩展和调度,适合高推理密度和多租户环境,有效处理多模型和多租户工作负载。
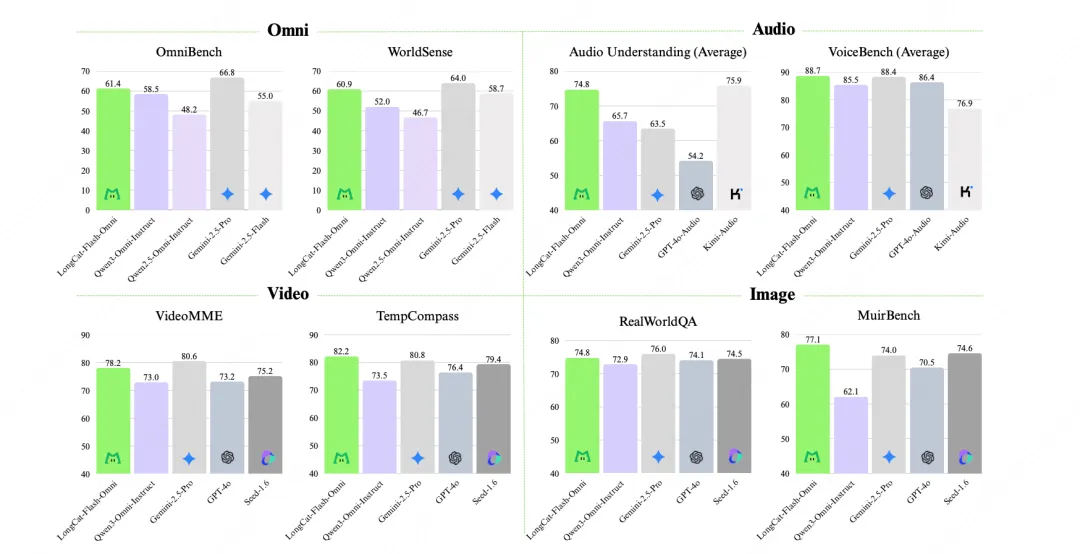
美团推出了LongCat-Flash-Omni模型,参数达到5600亿,支持低延迟音视频交互,表现优异。该模型在多模态任务中实现了开源最先进水平,具备强大的文本、图像、音频和视频理解能力,有效解决了推理延迟问题。
本文介绍了physical intelligence公司推出的实时动作分块技术,旨在提升视觉-语言-动作模型(VLA)的实时控制能力。该技术通过异步机制和修复方法,解决了模型推理延迟和动作不连贯的问题,使机器人能够更精确地执行复杂任务。
随着大语言模型的快速发展,分布式推理中的通信开销成为主要挑战。我们提出了一种新技术Sync-Point Drop(SPD),通过选择性减少注意力输出的同步,降低通信开销。SPD在保持模型准确性的同时,有效缓解了通信瓶颈,实现了约20%的推理延迟减少,准确率下降不足1%。
本研究提出了一种新的语音推测解码(SSD)框架,旨在解决自回归语音合成模型的推理延迟问题。SSD通过轻量级草稿模型生成候选标记序列,推理速度提高了1.4倍,同时保持了高保真度和自然性。
华为提出OmniPlacement方法,通过优化混合专家模型中的专家分配,降低推理延迟约10%,提升吞吐量。该方法动态调整专家优先级、冗余部署和实时调度,解决专家负载不均的问题,确保高负载下系统稳定运行,并计划开源。
该研究提出了FORTRESS框架,旨在解决大型视觉和语言模型在处理分布外故障时的推理延迟问题,实时生成安全后备策略,从而提高系统安全性和规划成功率。
本研究提出了一种资源感知的Transformer架构分区算法,旨在解决边缘环境中大型语言模型推理的内存过载和高延迟问题。该算法动态更新分区决策,优化注意力头的分配与迁移,实验结果表明推理延迟与最优解相差仅15%至20%,显著提升了推理速度和内存效率。
本研究提出共享RAG-DCache,通过共享磁盘键值缓存管理,解决大型语言模型推理延迟问题。该方法在多实例环境下显著提高推理吞吐量,提升15~71%,延迟降低12~65%。
本研究提出了一种高效的草拟模型,解决了大语言模型在投机解码中的记忆需求、短训练数据与长上下文推理的挑战,显著提升了长上下文任务的性能并减少了推理延迟。
本文讨论了基于Transformer的文本嵌入模型在参数增加时的推理延迟和内存使用问题。提出的Nomic Embed v2是首个通用的专家混合文本嵌入模型,性能优于同类模型,具有重要的应用潜力。
本研究提出了一种改进的Chinchilla扩展法,通过优化模型参数、训练标记和结构,Morph-1B模型在保持准确性的同时,推理延迟效率提高了1.8倍。
本研究探讨了大型语言模型在飞行轨迹预测中的应用,重构问题和构建数据集显著提高了预测准确性,但高推理延迟限制了实时应用。
本研究提出RE-POSE框架,旨在解决边缘设备实时物体检测中的计算资源限制和深度神经网络的高需求问题。通过强化学习驱动的动态聚类算法,优化了检测精度与延迟,并采用并行边缘卸载方案,显著提高了检测精度,减少了推理延迟,性能优于现有方法。
本研究提出了一种新方法,通过在边缘设备与中央服务器之间划分深度神经网络,解决资源受限设备中的语义分割推理延迟问题,实现数据本地处理,显著降低延迟。
本研究提出FluidML框架,以优化边缘设备上的机器学习模型推理,显著提升速度和内存效率。评估结果显示,推理延迟最多减少25.38%,峰值内存使用率降低41.47%。
本研究提出FiRST算法,旨在降低自回归大型语言模型在资源受限环境中的推理延迟。该算法通过自适应层选择和任务导向的微调,提高了部署效率和特定任务的准确性。
论文提出了一种“块注意力”机制,提高了RAG模型的效率和速度。通过将输入文本分块处理,专注于最相关部分,减少了推理延迟。实验表明,该方法在多项基准测试中表现优异,推理延迟降低50%。尽管对全局上下文处理不足,但为高效低延迟AI系统开发做出了重要贡献。
完成下面两步后,将自动完成登录并继续当前操作。