
LongCat-Flash-Omni 正式发布并开源:开启全模态实时交互时代
内容提要
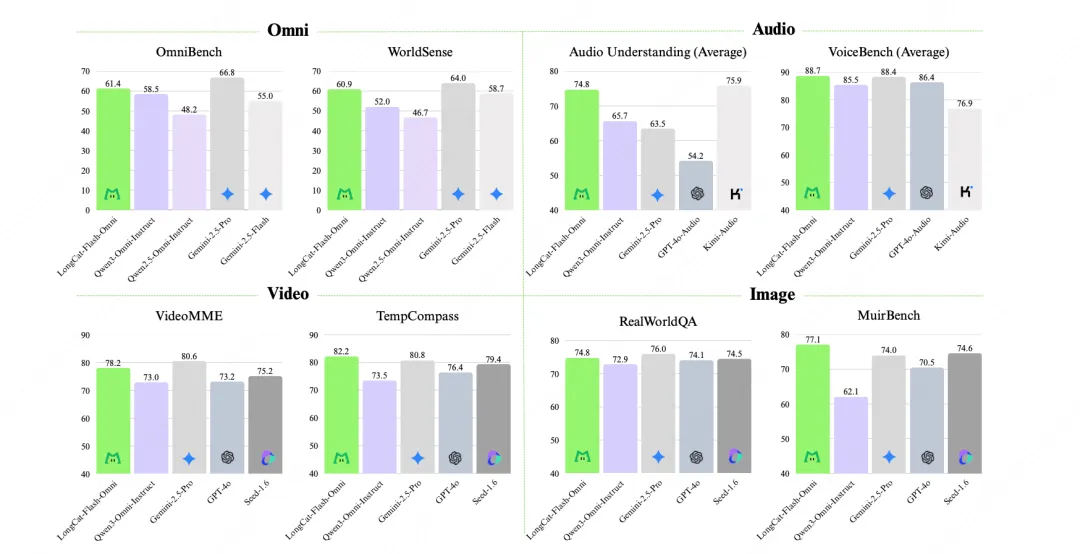
美团推出了LongCat-Flash-Omni模型,参数达到5600亿,支持低延迟音视频交互,表现优异。该模型在多模态任务中实现了开源最先进水平,具备强大的文本、图像、音频和视频理解能力,有效解决了推理延迟问题。
关键要点
-
美团推出LongCat-Flash-Omni模型,参数达到5600亿,支持低延迟音视频交互。
-
LongCat-Flash-Omni在多模态任务中实现了开源最先进水平,具备强大的文本、图像、音频和视频理解能力。
-
该模型采用高效架构设计,集成多模态感知模块与语音重建模块。
-
模型实现了毫秒级响应,解决了推理延迟问题。
-
LongCat-Flash-Omni支持128K tokens上下文窗口及超8分钟音视频交互,具备显著优势。
-
采用渐进式早期多模融合训练策略,确保全模态性能强劲且无单模态性能退化。
-
在综合性全模态基准测试中,LongCat-Flash-Omni表现优异,达到了开源最先进水平。
-
模型在文本、图像、音频、视频等各项模态的能力均位居开源模型前列。
-
LongCat-Flash-Omni在实时多模态交互中展现出显著优势,评分高于当前最优开源模型。
-
未来将进一步优化实时性、类人性与准确性等维度。
延伸解读
全模态交互的技术突破
LongCat-Flash-Omni模型在音视频交互中实现了毫秒级响应,解决了行业内普遍存在的推理延迟问题。这一技术突破使得实时多模态应用的开发变得更加高效,尤其适用于需要快速反馈的场景,如在线教育和虚拟助手等。
渐进式训练策略的优势
该模型采用渐进式早期多模融合训练策略,有效解决了不同模态数据分布的异质性问题。这种策略不仅确保了全模态性能的强劲,还避免了单模态性能的退化,为多模态模型的训练提供了新的思路。
与闭源模型的竞争
LongCat-Flash-Omni在多个基准测试中表现优异,尤其在视频理解和音频处理方面,其性能与闭源模型相当。这表明开源模型在技术上已具备与闭源模型竞争的能力,推动了整个行业的技术进步。
延伸问答
LongCat-Flash-Omni模型的主要特点是什么?
LongCat-Flash-Omni模型具有5600亿参数,支持低延迟音视频交互,具备强大的文本、图像、音频和视频理解能力。
LongCat-Flash-Omni如何解决推理延迟问题?
该模型采用高效架构设计和渐进式早期多模融合训练策略,实现了毫秒级响应,解决了推理延迟的痛点。
LongCat-Flash-Omni在多模态任务中的表现如何?
在综合性全模态基准测试中,LongCat-Flash-Omni达到了开源最先进水平,表现优异,尤其在文本、图像、音频和视频理解方面。
LongCat-Flash-Omni支持多长的音视频交互?
该模型支持超过8分钟的音视频交互和128K tokens的上下文窗口。
LongCat-Flash-Omni的训练策略有什么创新之处?
模型采用渐进式早期多模融合训练策略,逐步融入不同模态的数据,确保全模态性能强劲且无单模态性能退化。
LongCat-Flash-Omni与其他开源模型相比有什么优势?
LongCat-Flash-Omni在实时多模态交互中展现出显著优势,评分高于当前最优开源模型,且在各项模态能力上均位居前列。
