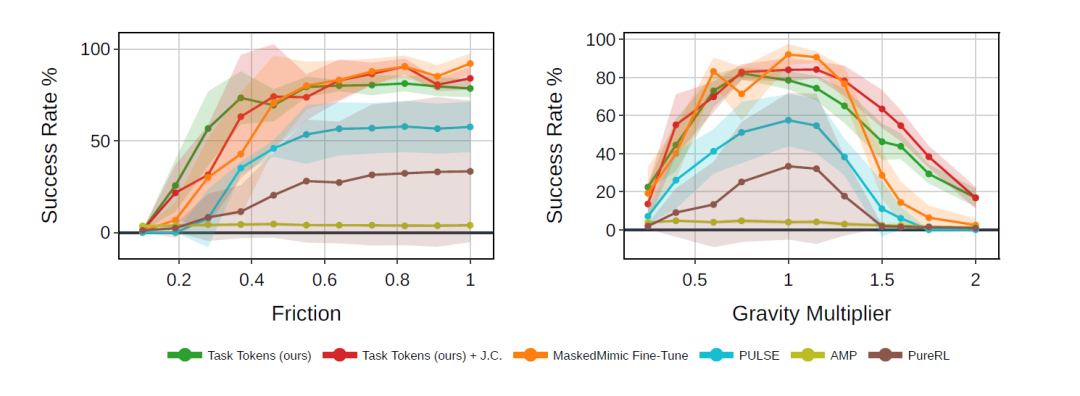
以色列理工学院的研究团队提出了一种名为 Task Tokens 的方法,旨在高效适配行为基础模型(BFM)到特定任务。该方法通过减少可训练参数和提高收敛速度,保持了模型的灵活性和泛化能力。实验表明,Task Tokens 在多种任务中表现优异,尤其在应对环境变化时展现出更强的鲁棒性。
本文探讨了终点损失的收敛速度改进,提出线性衰减学习率策略可实现$ ext{O}(1/ ext{sqrt}(T))$的收敛速度,优于常数学习率。通过推广核心恒等式,强调学习率调度的重要性,并展示了理论最佳的收敛结果。
谢赛宁团队的新研究表明,VAE时代已结束,RAE(表征自编码器)将取而代之。RAE结合预训练编码器与轻量解码器,提供高质量重建和快速收敛,尤其在图像生成方面表现优异,克服了VAE的多项局限。
我们提出了一种新颖的神经网络几何优化方法,结合量子Fisher信息几何与深度学习,展现出在多个量子系统中的优越性能。关键创新包括等变神经网络架构和黎曼优化算法,实验结果表明收敛速度提升3-5倍,达到理论最优值的95%以上。
本文探讨了Muon优化器的变体,提出通过放宽Gram矩阵约束设计多种流形约束优化器。Muon优化器通过正交化权重更新改善条件数,而流形Muon进一步将权重限制在特定几何形状上。研究表明,放宽约束可以在保持良好条件的同时提升优化器的灵活性和收敛速度。
本研究提出了一种有效的超参数调优方法μP,应用于扩散变换器,显著提升了模型的收敛速度和扩展性,尤其在文本到图像生成任务中表现突出,同时降低了调优成本。
本研究揭示了验证器错误导致强化学习模型输出被拒绝的问题。提出的轻量级验证器tinyV能够动态识别误判,提高奖励估计的准确性,实验结果表明其提升了通过率和收敛速度。
本研究提出了一种新型生成对抗网络α-GAN,采用Rényi交叉熵作为损失函数,解决了传统GAN的收敛速度和梯度消失问题。研究表明,Rényi阶α在(0,1)范围内能有效加速收敛,推动GAN的发展。
本研究提出了一种多态元启发式框架(PMF),通过自适应切换机制和实时反馈,动态选择算法,显著提高了高维、动态和多模态环境中的收敛速度和解的质量。
本研究提出了一种深度乘积单元残差神经网络(PURe),有效解决了深度卷积网络在表达能力和参数效率方面的问题。PURe在多个数据集上超越了深层ResNet,展现出更快的收敛速度和更强的抗噪声能力,显示了其在计算机视觉中的应用潜力。
本研究提出了一种新交叉算子粒子群优化启发交叉(PSOX),旨在改进实数编码遗传算法。PSOX结合全局最佳解和历史最优解,提升了收敛速度并保持了种群多样性。实验结果表明,PSOX在解决方案的精度和稳定性方面优于其他五种交叉算子。
本研究提出局部提示优化(LPO)方法,旨在解决大语言模型提示优化中的词汇复杂性问题。该方法在数学推理和BIG-bench Hard基准上显著提升了性能,并且收敛速度快于传统方法。
本研究分析了深度神经网络训练中不同优化方法的收敛速度,结果显示Adam优化器收敛速度较快,而RMSprop较慢。这为优化算法的选择提供了理论依据,提升了深度学习模型的训练效率。
本研究分析了粒子群优化算法在配置不明确时的低可靠性问题,探讨了不同通信拓扑对信息流和收敛速度的影响,提升了优化决策的可解释性,并提出了选择合适拓扑的建议。
三位普林斯顿数学家改进了经典牛顿法,提升了收敛速度和适用范围。新算法通过调整泰勒展开,更有效地处理复杂函数,尤其在初始点远离最小值时表现更佳。参与者包括华人学者Jeffrey Zhang,研究方向涵盖数据科学和优化。
本研究提出了一种新方法,通过自监督强化学习提高非线性系统中李雅普诺夫函数的推导效率,结果表明其在机器人任务中收敛速度更快、近似精度更高。
本文提出了一种新型初始化方法IDInit,旨在解决深度神经网络训练中的初始化问题,保持残差网络的身份一致性。研究表明,IDInit显著提高了收敛速度、稳定性和性能,适用于多种大型数据集和深度模型。
本文研究了经过梯度流训练的单隐藏层ReLU网络在$n$个数据点上的收敛性,发现宽度为$ ext{log}(n)$的网络能够高概率实现全局收敛,并揭示了收敛速度的渐近特征。
FitLight提出了一种新颖的联邦模仿学习框架,旨在解决基于强化学习的交通信号控制方法在实际应用中的高学习成本和泛化能力差的问题。该框架支持在各种交通环境中即插即用,显著提高了控制策略的收敛速度和资源使用效率。
本研究提出了一种高效的优化器设计方法,开发了RACS和Alice优化器,以解决大语言模型的低内存需求和快速收敛问题,显著提升了LLaMA预训练的收敛速度和性能。
完成下面两步后,将自动完成登录并继续当前操作。