本文提出了一种基于编码器-解码器网络的数学公式识别方法,结合语法规则和树遍历过程,显著提高了识别精度。实验结果表明,该方法在多个数据集上优于现有技术,并创建了一个包含10万个手写数学表达式图像的数据集,相关代码和模型将公开。
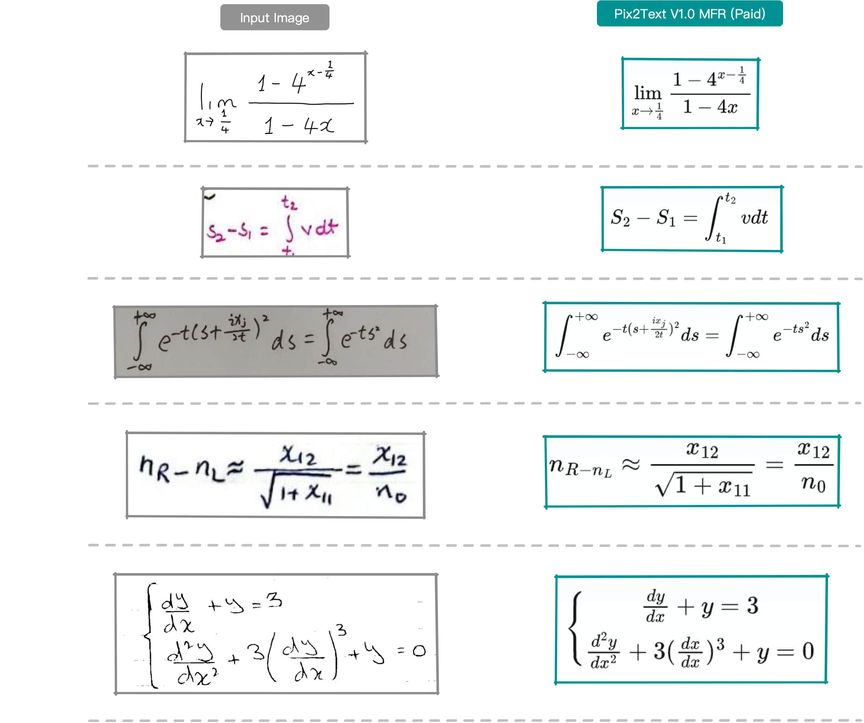
Pix2Text (P2T) V1.0 发布,推出了新的数学公式识别模型(MFR),显著提高了识别精度,成为开源领域的领先工具。该工具支持识别图片中的文字和数学公式,输出 LaTeX 表达式,旨在成为 Mathpix 的免费替代品。新版本移除了对旧模型的依赖,采用微软的 TrOCR 架构,支持多种语言,用户可免费使用网页版,每天识别上限为 10000 个字符。
Pix2Text (P2T) V1.0 发布,新增的数学公式识别模型(MFR)显著提升了识别精度,成为开源领域的领先工具。该工具支持识别图片中的文字和数学公式,并输出 LaTeX 表达式。P2T 采用小模型和开源策略,适合在普通 CPU 上运行。新版本移除了对旧项目的依赖,使用微软的 TrOCR 架构,识别效果优于之前的模型。用户可免费使用网页版,每天识别 10000 个字符。
本文提出了一种基于编码器-解码器网络的数学公式识别方法,通过加入语法规则和树遍历过程,减轻了结构预测误差。实验结果表明,该方法在三个基准数据集上的识别性能更好。作者还创建了一个包含10万个手写数学表达式图像的大规模数据集,并公开了源代码、新数据集和预训练模型。
本文提出了一种基于编码器-解码器网络的数学公式识别方法,通过加入语法规则和树遍历过程,减轻了数学公式识别中的结构预测误差。实验结果表明,该方法在三个基准数据集上取得了更好的识别性能。作者还创建了一个包含10万个手写数学表达式图像的大规模数据集,并公开了源代码、新数据集和预训练模型。
完成下面两步后,将自动完成登录并继续当前操作。