Arc Institute与加州大学合作开发的机器学习架构State,能够有效预测细胞在不同环境下的反应,准确率提高超过50%,尤其在基因表达识别方面表现突出。
本研究提出了一种模块化方法,针对自然语言接口中的歧义和欠规范性问题。该方法通过自然语言解释解决歧义,并将其映射到逻辑形式(如SQL查询),显著提高了解释的覆盖率和泛化能力。
AIxiv专栏促进学术交流,报道2000多篇内容。研究团队提出基于AI大模型的多模态语义通信框架(LAM-MSC),解决数据异构、语义歧义和信号衰落等问题,实现低延迟、高质量的通信体验。该框架通过统一语义表示、个性化理解和生成式信道估计等方法,提高多模态数据的传输效率和准确性。
本研究解决了低资源领域中命名实体消歧义的挑战,现有方法往往依赖训练数据或对领域特定知识库的适应性不足。文章提出了一种无监督的方法,利用组施泰纳树的概念,通过候选实体之间的上下文相似性来识别最相关的消歧义候选者,且在多个领域特定数据集中的Precision@1性能比现有最先进的无监督方法提高了40%以上。
本文提出的FAST-Splat方法克服了现有语义高斯色彩化的局限,能够实现精确的语义对象定位,并在训练和渲染速度及内存需求上优于传统方法。
本文针对翻译中单词在目标语言中可能具有多种变体的问题,提出了一种新方法。研究团队开发了DTAiLS数据集,并通过评估语言模型和神经机器翻译系统,发现GPT-4在不同语言中表现出67%到85%的准确率,并且使用语言模型生成的高质量词汇规则显著提高了较弱模型的准确性,部分情况下达到或超过GPT-4的表现。
本研究解决了深度网络在推理过程中对多个类别标签预测的歧义问题。通过现代分割和输入归因技术,我们提出了一种新框架,能够区分由不同实体驱动的标签或由同一实体驱动的标签,并提供反事实证明。该方法在ImageNet验证集的多个样本上表现出色,显示了其潜在影响。
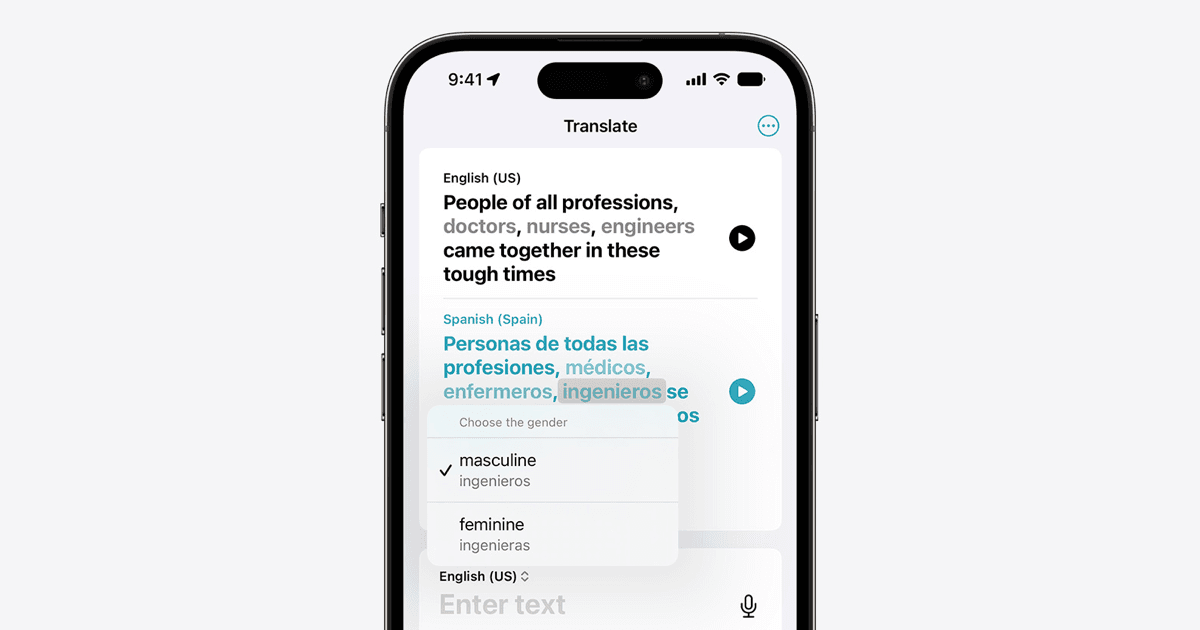
机器翻译在处理语法性别时遇到挑战。某些语言需要性别明确的词汇,而其他语言则是中性的。研究者开发了一种方法,让用户在翻译时选择合适的性别形式,无需额外计算负担。该方法已应用于苹果翻译应用,支持从英语到西班牙语、法语和葡萄牙语。研究还发布了数据集,推动领域发展。未来挑战包括扩展语言对和处理非二元性别。
本研究探讨了大型语言模型在数学问题求解中的能力,采用多种微调策略显著提升模型性能。尽管模型在常规任务上表现良好,但在复杂问题上仍面临挑战,需要进一步研究以提高其数学推理能力。
本研究介绍了AmbigQA任务,旨在解决开放领域问题中的歧义,并构建了AmbigNQ数据集,发现超过一半的问题存在歧义。提出的Refuel模型在AmbigQA数据集上表现优异,展示了多义性问题的解决方案。此外,研究还涉及时间问答数据集TempQA-WD和UnSeenTimeQA基准,评估语言模型在复杂推理中的表现。
该论文提出多种基于深度学习的定位方法,提升了机器人和视觉地理定位的精度与效率。通过2D-3D匹配、稀疏描述符分类和自适应k值分配等技术,显著降低了计算开销并提高了实时性,展示了在复杂环境中的应用潜力。
本文介绍了一种结合范畴论和量子力学的量子自然语言处理(QNLP)新方法,通过向量化词汇和使用组合密度语义学(DisCoCat)模型,提升了句子意义计算和词汇比较的效果。研究探讨了量子计算在自然语言处理中的应用,包括支持向量机分类和概率方法,并评估了实验结果,提出了改进模型的可能性。
本文探讨了大型语言模型(LLM)和transformer在表格数据处理中的应用,包括实体消歧、语义解释和推理性能提升。研究表明,LLM在表格推理和自动标注方面表现优异,并提出了新的数据集和评估框架,以推动未来研究的发展。
本论文研究了结构性解析对Transformer语言模型的影响,发现辅助训练能提升模型的句法推理能力。提出了一种基于语法规则的无监督句法树生成方法,结合强化学习和自编码器技术,在多个基准数据集上取得了优异结果,表明结构性监督显著改善模型表现。
本研究开发了一种自监督学习算法,应用于词义识别和消歧任务,展示了其在自然语言处理中的潜力。研究探讨了预训练语言模型的特征捕捉能力,提出了姓名消歧的新方法,并分析了语义碰撞对文本理解的影响。所提出的聚类算法和模型在多个数据集上表现出色,推动了相关领域的发展。
本文探讨了语言歧义在自然语言处理中的重要性,分析了大型语言模型(如ChatGPT)在识别和处理歧义方面的表现及局限性,并提出了改进方法和评估标准,呼吁提升算法性能和可解释性,以应对模糊文本和虚假信息的挑战。
通过利用神经微面场 (NMF) 作为一种先进的神经反渲染方法,本文旨在阐述反渲染的固有模糊性,并提出了一种评估框架来评估预估场景属性之间的补偿或相互作用程度,以探索这个不适定问题的机制和潜在缓解策略。实验结果强调了神经反渲染中的内在模糊性,并突出了通过几何、材料和照明先验提供额外指导的重要性。
本文提出了一个语言歧义数据集,测试预训练语言模型在识别歧义方面的表现,结果显示现有模型准确率仅为32%。研究强调语言歧义在自然语言处理中的重要性,并展示了多标签推理模型在识别虚假政治言论中的应用。提出通过用户澄清问题来解决模型歧义的方法,显著提高了模型性能。此外,研究探讨了大型语言模型在机器翻译和模糊任务中的应用,提出改进策略以提高准确性和应对不确定性。
本综述论文概述了图像超分辨率中的扩散模型(DMs),分析了特征和方法论。研究了替代输入域、条件策略、指导、失真空间和零样本方法。讨论了DMs在图像超分辨率中的演变、趋势、挑战和未来方向。
本文介绍了一种新型拉普拉斯和扩散动力学模型,应用于社交网络上的观点动态。通过网络上的扩散动力学演化意见和信息传递,处理可控性、可达性、有界信任度以及谐波延伸等问题。
完成下面两步后,将自动完成登录并继续当前操作。