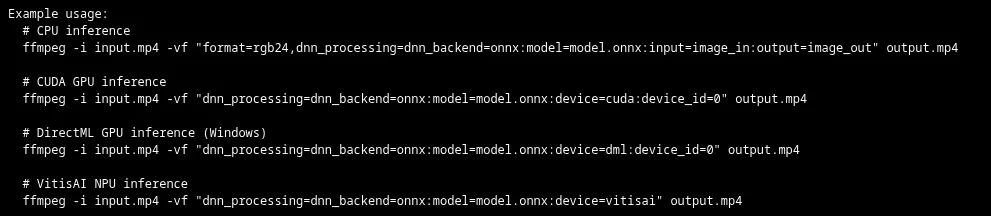
AMD 工程师为 FFmpeg 提供了 ONNX Runtime 后端,支持深度神经网络 (DNN) 滤镜,允许在视频处理过程中使用 AI 模型,兼容多种 GPU 和 NPU 平台,包括 NVIDIA CUDA 和 AMD Ryzen AI NPU,增强了 FFmpeg 的视频处理能力。
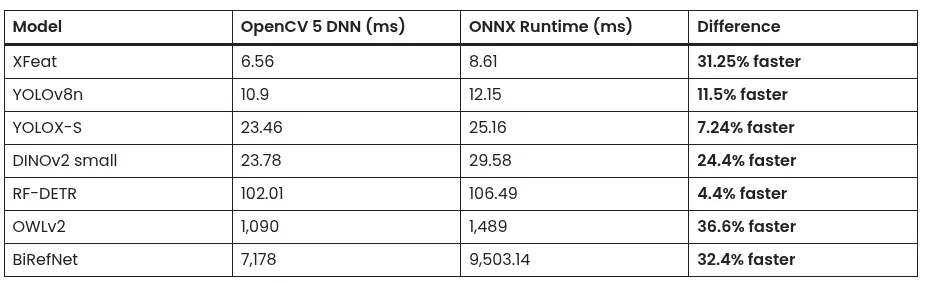
OpenCV 5.0于2026年6月6日发布,新增深度神经网络引擎重写、80% ONNX覆盖率和内置大型语言模型支持等功能,并针对多种硬件进行了优化,计划实现原生GPU支持。
Triton是一种基于Python的并行编程语言和编译器,旨在高效编写自定义深度神经网络计算内核,并在现代GPU上运行。它提供了多种处理张量的函数,如argmax、argmin、max、min、reduce和sum。
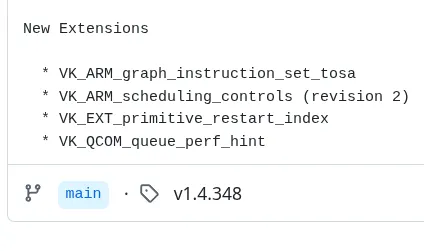
Vulkan 1.4.348 更新了四个新扩展,包括支持深度神经网络的 VK_ARM_data_graph_instruction_set_tosa 和自定义图元重启索引的 VK_EXT_primitive_restart_index。此外,高通的 VK_QCOM_queue_perf_hint 提供功耗限制提示。NVIDIA 也发布了新驱动程序,支持多个扩展并修复了一些问题。
Triton 是一种基于 Python 的并行编程语言和编译器,旨在高效编写自定义深度神经网络计算内核,以实现现代 GPU 的最大吞吐量。
Triton 是一种基于 Python 的并行编程语言和编译器,旨在高效编写自定义深度神经网络计算内核,并在现代 GPU 上实现最佳性能。
大模型是由深度神经网络构建的,参数量达到数十亿,广泛应用于自然语言处理和计算机视觉等领域,具备强大的泛化能力。joycoder工具可用于代码评审和安全检查,帮助生成测试用例,提高测试效率。
Triton 是一种基于 Python 的并行编程语言和编译器,旨在高效编写深度神经网络计算内核,以实现现代 GPU 的最大吞吐量。
Triton是一种基于Python的并行编程语言和编译器,旨在高效编写自定义深度神经网络计算内核,以实现现代GPU的最大吞吐量。
Cognizant AI实验室获得两项新美国专利,总数达到59项,并在西班牙GECCO大会上获金奖。这些专利涉及深度神经网络的协同进化和优化损失函数,旨在提升模型性能和训练效率。
Triton是一种基于Python的并行编程语言和编译器,旨在高效编写自定义深度神经网络计算内核,并在现代GPU上实现高吞吐量运行。
本研究提出了一种基于热风速仪的微型无人机气流惯性里程计,解决了低成本传感器的偏差问题。通过融合多传感器数据,利用深度神经网络有效估计飞行状态和气流速度,显著减少位置漂移,实现了在无风环境中的准确飞行速度估计。
AI通过声波生成声谱图,利用深度神经网络进行声学建模,并结合语言模型和置信度评分,识别“eight”和“ate”的区别。
本研究提出了一种基于关键路径的深度神经网络异常检测方法。该方法通过提取关键路径并运用遗传算法,有效识别与正常输入显著不同的异常输入激活模式。实验结果表明,该方法在异常检测中表现优异,适用性广泛。
本研究提出了速度正则化Adam(VRAdam),旨在解决传统优化算法在训练深度神经网络时的振荡和收敛问题。VRAdam通过引入基于速度的惩罚项,优化动态学习率,从而提升了图像分类和语言建模等任务的性能。
本文探讨医学影像中人机对齐与公平性问题,揭示深度神经网络在不同人群中的偏见。研究表明,结合人类洞察可减少公平性差距,但过度对齐可能影响性能,强调需采用精准策略。
本研究提出了一种新方法Adaptive Linearization(AdaLin),旨在解决深度神经网络在非平稳环境中学习能力下降的问题。AdaLin通过动态调整激活函数,显著提升了持续学习能力。
完成下面两步后,将自动完成登录并继续当前操作。