
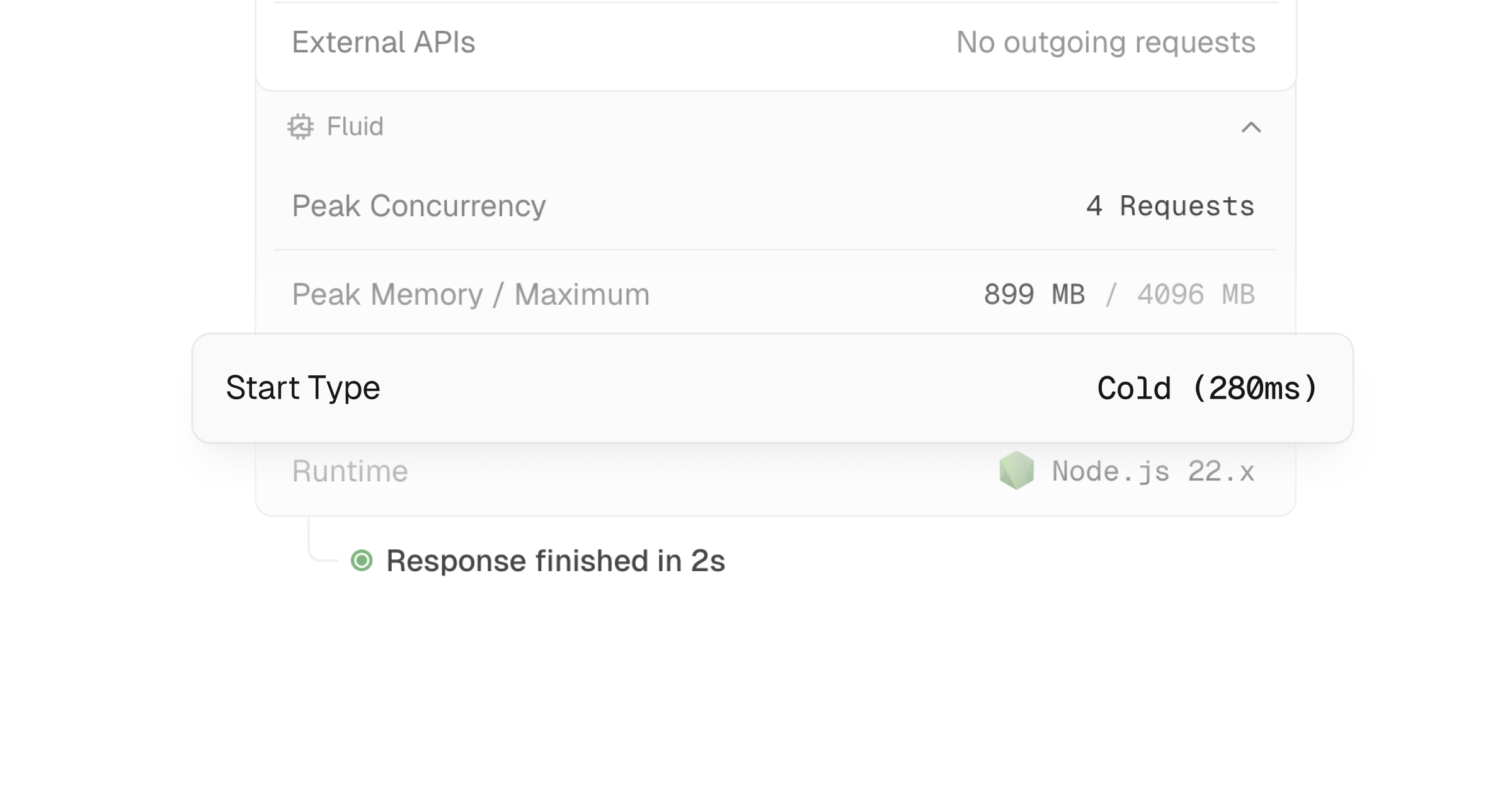
运行时日志中现已提供函数启动类型
Vercel News
·




使用GraalVM原生镜像的Lambda函数 - 第4部分:测量不同内存设置下的冷启动和热启动时间
DEV Community
·

AWS SnapStart - 第26部分:使用不同垃圾回收算法测量Java 21的冷启动和热启动
DEV Community
·
Vercel 函数现在具有更快的启动速度和更少的冷启动
Vercel News
·
