AI智能体的生成能力迅速提升,但验证能力未能跟上,导致“生成-验证差距”。这一差距使得模型在自我修正时无法识别错误,甚至可能放大错误信念,影响系统的可靠性。为解决此问题,建议引入外部验证机制和多样性验证,并限制自我修正的轮数,以提升模型的输出质量和安全性。
近年来,开放源代码的全能AI模型逐渐成熟,能够统一处理文本、图像、音频和视频。本文介绍了五个前沿模型:NVIDIA的Nemotron 3、Google的Gemma 4、Qwen3-Omni、DeepSeek的Janus-Pro和MiniCPM-o 4.5。这些模型在多模态理解、实时交互和生成能力方面表现出色,适用于客户支持、文档分析和实时语音对话等应用场景。全能模型的出现使AI在实际工作流程中更加高效和自然。
智象未来在北京发布了图像大模型HiDream-O1-Image-Pro,该模型基于原生全模态架构,参数超过200亿,刷新多项基准测试纪录。公司完成新一轮融资,显示市场对原生全模态模型的信心。该模型通过统一图像、文本和任务条件,提升生成和泛化能力,推动AI向理解和构建世界的方向发展。
大型语言模型表明,语言的本质在于其生成能力,而非对现实的描述。人类语言的使用类似于预测,语言的意义在于引发的后续行动,而非固定的事实。
国产视频模型SkyReels-V4近期在全球视频大模型排行榜中跃升至第二位,展现出强大的多模态生成能力,支持文本、图像、视频和音频的组合输入,实现精准控制和专业级视频修复,推动视频创作全流程一体化。
文心5.0正式发布,支持文字、图像、音频和视频的全模态输入与输出,具备强大的理解与生成能力。其在多模态理解和情感分析方面表现突出,能够精准捕捉细节并进行复杂推理。新技术采用统一架构,提升训练与推理效率,参数规模超过2.4万亿,标志着百度在大模型领域的突破。
李飞飞在文章中指出,AI的下一个发展方向是空间智能,强调其重要性与复杂性。她讨论了大语言模型的局限性,定义了空间智能及其实现方法,强调生成能力、多模态能力和状态预测。她的研究对未来AI发展具有重要意义。
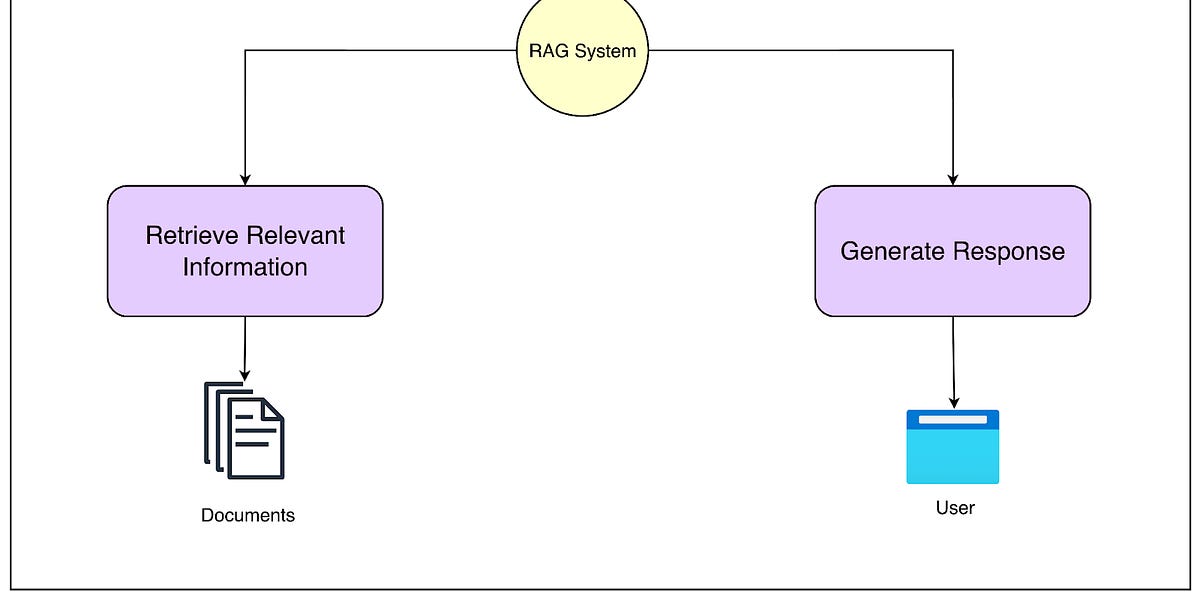
RAG(检索增强生成)结合了信息检索与生成能力,克服了大型语言模型在商业应用中的局限性。通过访问特定文档,RAG能够提供准确且具体的答案,适用于需要私密信息、实时更新和高准确度的场景。
本研究提出WixQA基准,解决企业问答系统领域特定数据集不足的问题,通过构建多样化的问答数据集来评估检索与生成能力。研究表明WixQA有效支持企业环境中的RAG系统评估。
本研究提出了CodeMixBench基准,用于评估大型语言模型在混合代码提示下的生成能力。研究发现,混合提示会导致模型性能下降,尤其是小型模型,揭示了多语言代码生成的挑战及未来发展方向。
本研究提出了一种新框架,将大型语言模型(LLMs)视为上下文敏感的语言生成器。通过分析变压器的上下文窗口和注意机制,揭示了其生成类人智能输出的能力,弥合了形式语言理论与变压器生成能力之间的鸿沟。
本研究提出CAFe框架,首次在大型视觉语言模型中同时提升表征学习与生成能力,推动多模态检索与生成基准的发展。
本研究探讨了大型语言模型(LLMs)内部编码的事实知识与其输出之间的差距,发现内部知识显著高于外部表达,平均差距达到40%。这一发现揭示了LLMs生成能力的局限性。
本研究提出TRCE方法,针对文本到图像扩散模型中的恶意内容生成问题,采用双阶段概念消除策略,有效去除恶意概念,同时保留生成能力。
Anthropic推出Claude 3.7 Sonnet,这是首个结合逻辑推理与生成能力的混合推理模型,支持用户在聊天中自由切换模式。该模型在数学和编码任务中表现出色,开发者可利用Claude Code进行自主编码。尽管公司仍在亏损,但融资成功后估值将达615亿美元。
复旦大学研究团队提出的DuMo网络有效解决了生成模型中风险概念的精准擦除问题,同时保持了生成能力。在裸露内容、卡通和艺术风格的擦除任务中,该方法表现优异,达到了当前最佳水平,确保了安全概念的生成质量。
本研究提出了一种新方法,通过反向翻译自然语言代码切换句子并微调大语言模型,提升生成能力。结果显示文本流畅性良好,但评估指标与人类判断存在不一致。
本研究针对图神经网络(GNNs)可信度不足的问题,提出了分类法和框架,并调查了代表性方法。结果显示,大型语言模型(LLMs)与GNNs结合可提升其语义理解和生成能力。
本研究提出了一种名为“提升与跳过”的无引导扩散方法,旨在提高少数样本的生成能力。该方法通过对标准生成过程进行两个小改动,显著提升了生成效率,优于传统的引导方法。
华为诺亚方舟实验室提出的多模态大模型ILLUME,整合视觉理解与生成能力,使用约1500万图文对数据,展现出卓越的多模态任务性能。通过自提升多模态对齐策略,促进理解与生成能力的协同进化。
完成下面两步后,将自动完成登录并继续当前操作。