本研究探讨了深度学习中频率估计与贝叶斯推断在参数估计中的取舍。比较线性模型和浅层神经网络后发现,平均点估计通常优于后验推断,但后者在某些低维问题中仍具竞争力。这为理解两种方法的有效性提供了重要见解。
该研究提出了一种新型神经网络“中介网络”,结合深度学习与线性模型,专为表格数据设计。它通过深度超网络生成可解释的线性模型,兼顾高准确性与透明解释,成功解决了可解释性与性能之间的矛盾。
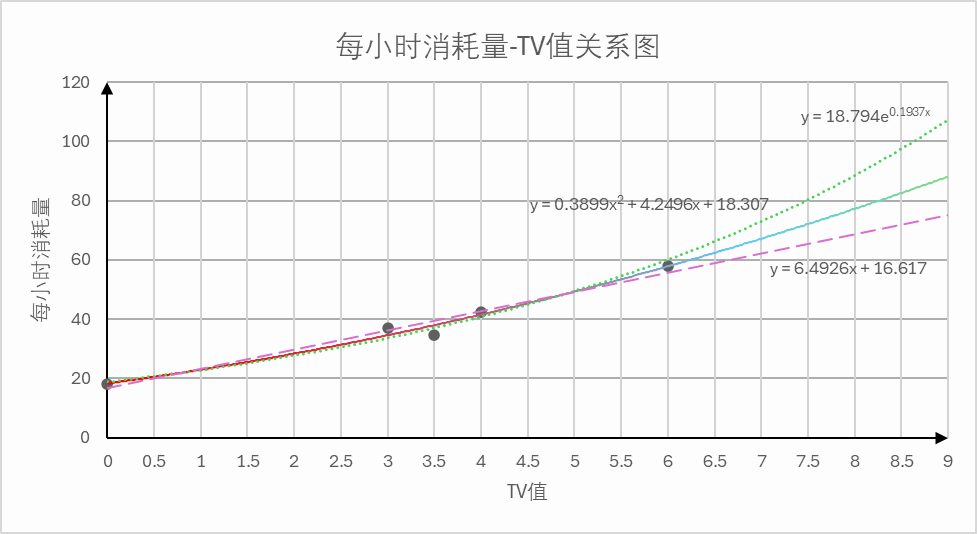
文章探讨了产线燃气耗量与工艺参数TV之间的关系。数据分析表明,TV越大,燃气耗量越多。建立了线性和非线性模型进行拟合,尽管初步模型误差在可接受范围内,但在某些情况下预测误差较大,需要采用更精确的迭代法进行改进。
本文探讨了线性模型在时间序列预测中的应用,提出了TSMixer模型,显示出优于现有模型的性能。研究强调交叉变量和辅助信息的重要性,并展示多尺度分解和自适应机制在提升预测效果方面的有效性。实验结果表明,TSMixer及其变体在多种时间序列任务中表现出色。
本文介绍了一种优化线性模型对抗训练的新算法,解决了大规模训练时的低效问题。通过专用求解器,提高了回归和分类问题的训练速度和效率,增强了线性模型在对抗环境下的表现。
Adam优化器结合动量和RMSProp方法,用于梯度下降。初始化时需提供参数生成器、学习率(默认0.01)、动量系数(默认0.9和0.999)、epsilon(默认1e-08)、权重衰减(默认0),以及AMSGrad等选项。不能同时启用foreach和fused,或differentiable和fused。使用step()更新参数,zero_grad()重置梯度。示例中,Adam优化器用于简单线性模型。
本研究首次揭示了注意力架构中标记选择的良性过拟合问题及其机制,重点研究线性模型和两层神经网络的收敛性,为后续研究提供新视角。
该研究探讨了机器学习模型的可解释性,发现线性模型比BERT模型更易于操控。提出了一种基于诚实度的局部元解释技术,以增强用户个性化解释。研究评估了解释系统与预测准确性之间的关系,强调准确性比可解释性更重要,并指出不同子组的解释质量存在公平性挑战。
该文章介绍了处理机器学习中数据分布不一致性的方法,包括基于训练环境的公平性方法和在线性模型中的性能展示。作者还介绍了其他相关算法和实验结果,证明了这些方法的优越性。
本文研究了线性模型在时间序列预测中的能力,并提出了基于多层感知机的模型TSMixer。TSMixer在学术基准测试和真实世界的M5基准测试中表现出良好性能,强调了利用交叉变量和辅助信息提高时间序列预测性能的重要性。预计TSMixer的设计将为基于深度学习的时间序列预测带来新的视野。
该研究提出了一种使用新方法训练的深度超网络来生成可解释的线性模型的方法。实验结果表明,该可解释的深层网络在表格数据上与最先进的分类器一样准确,并具有与最先进的解释技术相当的解释能力。
该研究提出了一种使用新方法训练的深度超网络来生成可解释的线性模型的方法,实现了黑匣子深度模型的准确性和自由的可解释性。在表格数据上与最先进的分类器一样准确,在实际预测中也具有与最先进的解释技术相当的解释能力。
该研究提出了一种用于基因组关联研究的标准线性模型,具有准确转换、快速算法和有效计算边缘似然的三个创新点。已成功应用于多发性硬化的大规模关联研究。
该研究使用对称等变性注意力机制,应用于自学习蒙特卡洛方法,成功提高了线性模型的接受率。在二维格上的自旋-费米模型中观察到类似于大型语言模型的缩放率的接受率。
该文提出了一个在切线特征空间中理解线性模型的框架,通过特征的线性变换得到一个具有双线性插值约束的联合优化问题,证明了该问题等价于一个线性约束优化问题,具有结构化正则化,鼓励近似低秩解。作者通过实验证明,在 MNIST 和 CIFAR-10 上,切线特征分类的自适应特征实现的样本复杂性比固定切线特征模型低一个数量级。
研究发现大型语言模型中神经元与特征对应关系不清晰,使用玩具模型观察到了特征叠加现象,可以实现超出线性模型的压缩,但需要非线性滤波的干扰。目前还不清楚如何将其推广到真实网络。
本文研究了双层全连接神经网络的早期学习动态,并证明了通过训练简单的线性模型可以模仿其行为。研究还发现这种简单性可以在更多层和具有卷积结构的网络中持续存在。
本文从贝叶斯角度出发,研究线性模型的训练速度与边缘似然之间的联系。发现训练速度可估计边缘似然,并预测线性模型组合中模型的相对权重。实验证明这种直觉在深层神经网络中也成立,为解释随机梯度下降训练的神经网络偏向良好泛化函数提供新方向。
完成下面两步后,将自动完成登录并继续当前操作。