

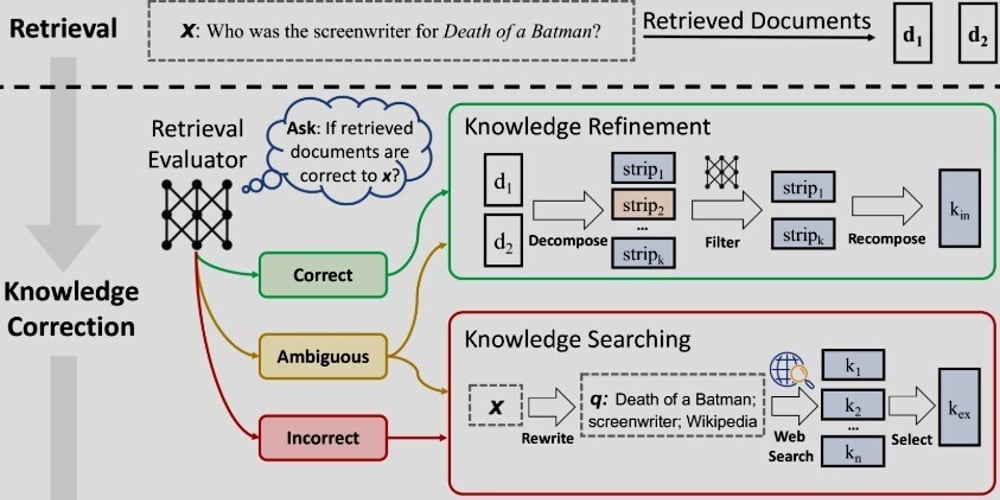
自我纠正的检索增强生成:提升AI语言模型的鲁棒性
DEV Community
·



大型语言模型的推理能力
DEV Community
·

赋予家庭机器人一些常识
MIT News - Computer Science and Artificial Intelligence Laboratory (CSAIL)
·
