本研究提出了DualOptimizer,通过自适应学习率和解耦动量因子,解决了现有机器遗忘方法在超参数上的敏感性问题。实验证明,该方法显著提高了机器遗忘的有效性和稳定性,适用性广泛。
本研究提出低张量秩适应(LoTRA)方法,优化Kolmogorov-阿诺德网络在迁移学习中的微调过程,通过自适应学习率策略提升训练效率,并验证其在偏微分方程等任务中的有效性。
论文提出了一种改进的CMA-ES算法,通过自适应学习率提升黑箱优化问题的性能。该方法动态调整学习率,实验显示在多种基准函数上优于标准CMA-ES。自适应学习率通过指数和乘法噪声机制实现,显著提高了收敛速度和解的质量。尽管超参数敏感性分析不足,但为进化优化算法提供了改进方向。
本文介绍了一系列针对对抗性多臂赌博问题的新算法,利用Tsallis熵进行正则化,并证明了其最小极大后悔度。研究涵盖多种分布的扰动方法,提出了新的算法框架和自适应学习率,探讨了算法的最优性及实际应用表现。
本文探讨了损失海森矩阵在多项分类任务中的演化及其对训练动态的影响。研究表明,优化轨迹应避免高曲率区域,以提高学习率的稳定性。分析不同步长调节器的表现发现,Polyak步长优于Armijo线搜索。此外,提出了一种自适应学习率算法,利用曲率信息自动调整学习率,显著提升深度神经网络的性能。
本文介绍了一种名为ADA-NSTORM的方法,利用自适应学习率解决组合型最小极大优化问题,比NSTORM更有效。该方法推动了组合型最小极大优化的发展,保证了分布鲁棒性和策略评估的关键能力。
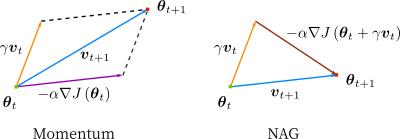
本文介绍了神经网络中的优化算法,包括批量梯度下降(BGD)、随机梯度下降(SGD)和小批量梯度下降(MBGD)。BGD计算开销大,SGD速度快但不保证损失函数每次减小,MBGD结合了两者优点。文章还讨论了Momentum、NAG、AdaGrad、Adadelta、RMSprop、Adam等自适应学习率方法及其优缺点,强调了不同算法在收敛速度和效果上的差异。
完成下面两步后,将自动完成登录并继续当前操作。