
深度学习优化算法
内容提要
本文介绍了神经网络中的优化算法,包括批量梯度下降(BGD)、随机梯度下降(SGD)和小批量梯度下降(MBGD)。BGD计算开销大,SGD速度快但不保证损失函数每次减小,MBGD结合了两者优点。文章还讨论了Momentum、NAG、AdaGrad、Adadelta、RMSprop、Adam等自适应学习率方法及其优缺点,强调了不同算法在收敛速度和效果上的差异。
关键要点
-
在构建神经网络模型时,选择合适的优化算法至关重要。
-
常用的优化算法包括批量梯度下降(BGD)、随机梯度下降(SGD)和小批量梯度下降(MBGD)。
-
BGD计算开销大,但每次更新沿着全局梯度的负方向。
-
SGD速度快,但不保证每次损失函数减小。
-
MBGD结合了BGD和SGD的优点,使用小批量样本进行梯度计算。
-
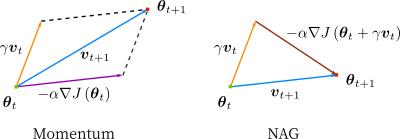
Momentum方法通过添加动量项加速收敛,解决SGD在峡谷形梯度中的问题。
-
NAG是Momentum的变种,利用下一步的梯度来更新当前梯度。
-
AdaGrad自适应学习率,适合处理稀疏数据,但可能导致学习率过小。
-
Adadelta改进了AdaGrad,使用固定长度的滑动窗口内的梯度。
-
RMSprop是Hinton提出的改进算法,解决了AdaGrad的学习率衰减问题。
-
Adam结合了Momentum和RMSprop,计算每个参数的自适应学习率。
-
Nadam将Adam与NAG结合,进一步提高了收敛速度。
-
AMSGrad是Adam的变体,使用历史平方梯度的最大值以保证收敛性。
-
不同优化算法在收敛速度和效果上存在显著差异。
延伸解读
优化算法选择的重要性
在构建神经网络时,选择合适的优化算法对模型性能至关重要。不同算法在收敛速度和效果上存在显著差异,开发者应根据具体任务和数据特性来选择最适合的算法,以提高模型的训练效率和准确性。
自适应学习率的优势与局限
自适应学习率算法如AdaGrad、RMSprop和Adam等,能够根据参数的历史梯度动态调整学习率,适应不同特征的学习需求。然而,这些算法也存在学习率衰减过快的问题,可能导致模型在训练后期无法继续学习,因此在使用时需谨慎调整超参数。
SGD与Momentum的比较
随机梯度下降(SGD)虽然训练速度快,但在某些情况下可能无法保证损失函数每次都减小。相比之下,Momentum通过引入动量项,能够加速收敛并有效应对峡谷形梯度问题。开发者在选择时应考虑模型的具体需求和数据特性。
延伸问答
什么是批量梯度下降(BGD)?
批量梯度下降(BGD)是梯度下降算法的一种形式,它在每次更新时使用整个训练集计算梯度,计算开销较大,但每次更新沿着全局梯度的负方向。
随机梯度下降(SGD)有什么优缺点?
随机梯度下降(SGD)速度快,但不保证每次损失函数减小,可能导致不稳定的收敛。
小批量梯度下降(MBGD)是如何工作的?
小批量梯度下降(MBGD)结合了BGD和SGD的优点,通过使用小批量样本计算梯度来更新参数,平衡了计算效率和收敛性。
Momentum方法如何改善SGD的收敛速度?
Momentum方法通过添加动量项来加速收敛,帮助SGD在峡谷形梯度中更快地找到最优解。
Adam算法与RMSprop有什么区别?
Adam算法结合了Momentum和RMSprop,计算每个参数的自适应学习率,而RMSprop主要通过历史平方梯度的指数衰减来调整学习率。
AMSGrad算法的主要改进是什么?
AMSGrad算法使用历史平方梯度的最大值而非滑动平均来更新参数,以保证收敛性,解决了RMSprop和Adam在某些情况下无法收敛的问题。
