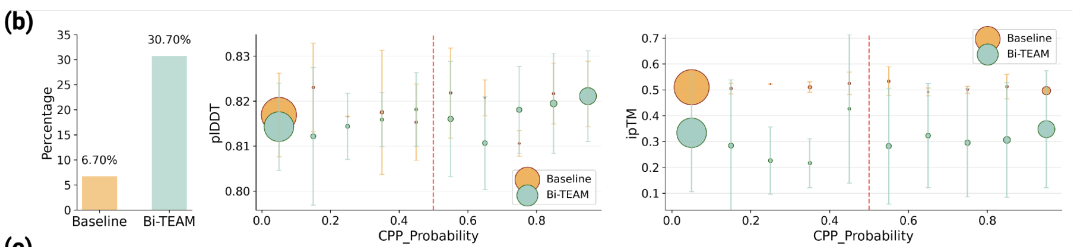
表征学习在生物化学与分子工程中愈发重要,尤其在肽的结构与功能建模方面。香港中文大学提出的Bi-TEAM框架通过整合生物与化学信息,提高了肽设计的准确性和成功率,特别是在细胞穿透性环肽的设计中表现优异,为药物研发提供了新技术路径。
本研究探讨了小鼠视觉皮层的神经表征及其与深度学习模型的对齐,提出了一种通用的表征学习策略,显著提升了模型在实际任务中的鲁棒性,为基于小鼠视觉的AI模型发展提供了新框架。
本研究提出了一种统一的信息论方程,概括了表征学习中多种损失函数的多样性。研究发现多种机器学习方法能够最小化KL散度积分,支持聚类、谱方法和对比学习,并开发了新损失函数,使ImageNet-1K的无监督分类性能提升超过8%。
本研究提出CAFe框架,首次在大型视觉语言模型中同时提升表征学习与生成能力,推动多模态检索与生成基准的发展。
本研究提出了Sorcen框架,旨在解决表征学习与生成建模的统一问题。通过引入新型协同对比重建目标“回声对比”,消除了对额外图像裁剪的需求。实验结果表明,Sorcen在多个指标上超越了以往方法,效率提升达60.8%。
本研究提出了一种新颖的音视频嵌入学习方法,结合跨模态三重损失与逐步自我蒸馏,解决了标签引导导致的性能不足问题。该方法通过动态优化软对齐,提升了表征学习,有效捕捉内在关系,从而提高音视频嵌入性能。
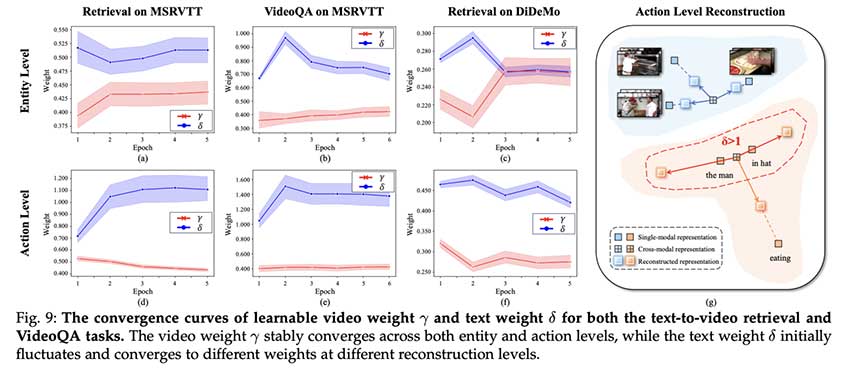
视频语言表征学习关注视频与文本描述的关系,HBI V2通过博弈论解决细粒度对齐问题,结合单模态和跨模态表征,提升了视频语言学习的效果。HBI V2在多项任务中表现出色,展现了其灵活性和有效性。
本文探讨了机器人视觉表征学习的局限性,提出利用语义三维关键点和半监督训练的方法,以提升精度至毫米级。介绍了DIAL和Voltron等新方法,通过语言标签和多模态模型改善机器人学习能力,增强其在新指令和复杂任务中的表现。此外,研究了结合模仿与强化学习的方法,以提高机器人在新环境中的适应性和技能优化。
本研究提出SimSiam+VAE方法,结合变分自编码器(VAE)与SimSiam网络,提升表征学习效果并捕捉不确定性。实验结果表明,该方法在多角色动态交互中优于SimSiam和VI-SimSiam,促进智能体间的理解与语言发展。
本文提出了一种无监督的降噪表征学习方案和Degradation-Aware SR网络,能够有效区分图像降级并提取判别性表征。实验结果表明,该方法在合成和真实图像上均表现优越,显著提升了超分辨率图像恢复的准确性和视觉效果。
本文提出了一种无监督序列解缠框架,结合矩乘自编码器和变分自编码器,实现序列数据的分离和可解释表征学习。实验结果表明,该模型在视频、音频和时间序列任务中表现优异,超越现有技术,证明了其在解缠和生成序列数据方面的有效性。
本文介绍了一种无监督的降噪表征学习方案及Degradation-Aware SR网络,能够有效区分图像降级并提取判别性表征。研究表明,该方法在合成和真实图像上表现优越,适用于盲图像超分辨率和多种降级情况,显著提升了图像恢复的准确性和细节。
本文介绍了一种基于规范相关分析的神经网络表示比较方法,提出了相似度指数来测量表示相似性。研究表明,神经网络的表征学习与模型架构、学习速率等因素密切相关,不同层之间的动态表现出层级相关性。通过分析,提出了改进神经网络评估方法的框架,并探讨了处理离域样本时的表现与相似性度量的关系。
本文探讨了自编码器在表征学习中的研究进展和机制,分析了信息分离和分层组织特征的三种机制,讨论了隐式和显式监督的重要性,通过失真率理论分析了自编码器表征学习的优缺点和任务需求。
该文介绍了一种名为RAILD的预测方法,能够学习未见实体和关系的表征,实验表明RAILD在知识图谱任务上性能显著提高。
本文介绍了深度学习研究中摒弃平衡数据假设的策略,采用表征学习等方法逼近现实世界中的数据不平衡问题。同时,文章指出在 SEP 预测中解决数据不平衡问题对成功至关重要。
本文提出了一种基于混淆平衡表征学习的非线性 CIV 回归,CBRL.CIV,以消除混淆偏差并平衡观察到的混淆因素。实验证明了 CBRL.CIV 在处理非线性情况方面的优越性。
本研究提出了一种新的速度协同增强方法,通过随机改变音视频数据的播放速度,增加了音视频配对的多样性,使负配对数量翻倍,从而显著增强了学习到的表征。同时,该方法改变了音视频配对之间的严格相关性,引入了增强配对之间的部分关系,由提出的SoftInfoNCE损失来建模,进一步提升了性能。实验结果表明,该方法显著改善了学习到的表征。
该论文提出了一种动态线性偏差融合方案,用于高维且不完整数据的表征学习。该方案通过建立二进制权重矩阵来动态切换线性偏差的状态,实现了非负潜在因子分析模型的动态线性偏差。实证研究表明,该方案的模型在三个真实应用领域的高维且不完整数据集上获得了较高的表征准确度,并具有高竞争力的计算效率。
表征学习是深度学习中的概念,通过预训练特征提取器将原始数据转换为低维特征,降低对数据和计算能力的需求。常见的特征提取方法包括视觉、光流、音频和文本。Masked Autoencoder (MAE)是一种前沿的表征学习模型,通过遮盖输入图像的随机块进行重建,可以高效地训练大型模型。MAE还可以扩展到视频领域。使用预训练模型可以在自己的任务上获得更好的效果。
完成下面两步后,将自动完成登录并继续当前操作。