MultiScene360数据集是一个多摄像头视频数据集,旨在推动生成视觉AI应用,特别是3D数字人技术。它提供同步的多视角视频,支持数字人神经渲染、虚拟角色视图合成和动作转移,包含13种场景和4个同步摄像头视角,适用于开发更真实的虚拟角色和动画工具。
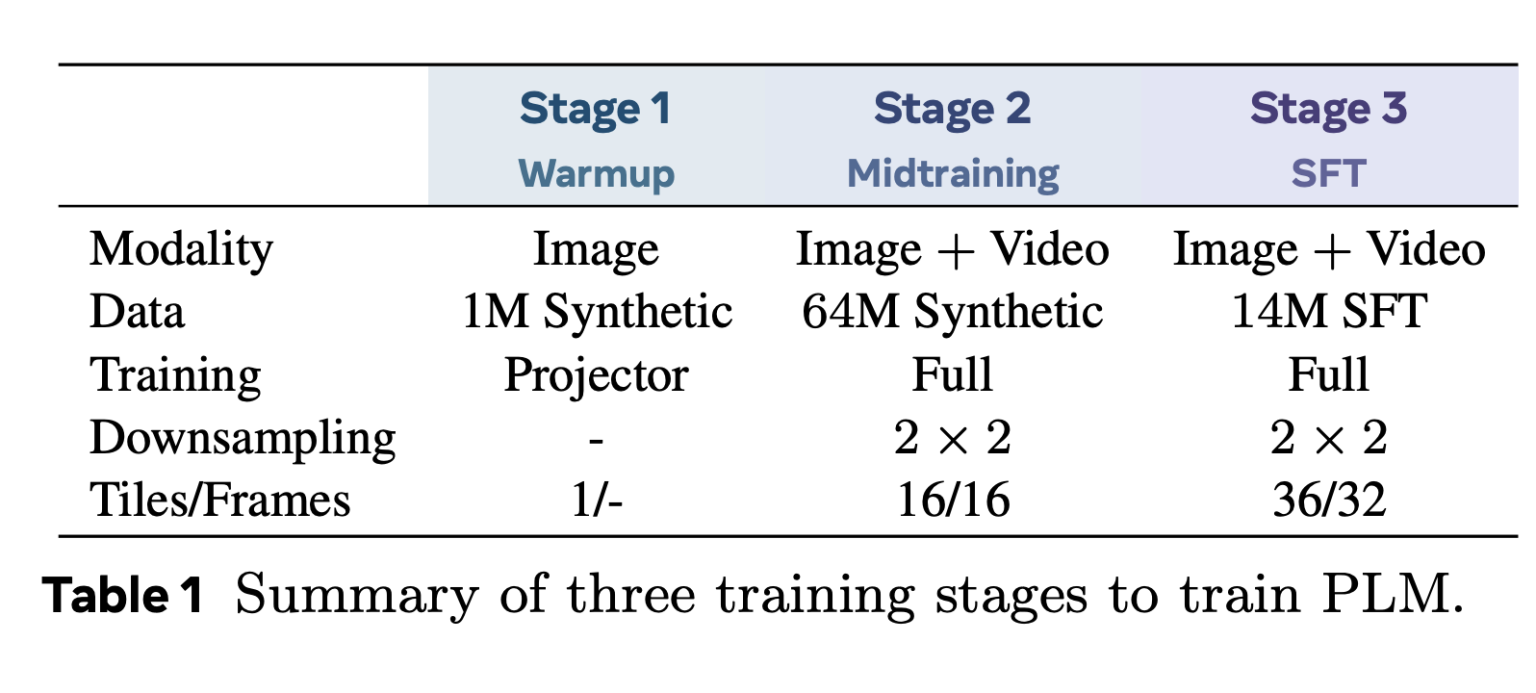
Meta AI推出了感知语言模型(PLM),这是一个开放且可复现的视觉语言建模框架,支持图像和视频输入。PLM通过合成数据和人工标记数据进行训练,强调透明性和可评估性,集成了视觉编码器和不同参数的语言解码器,采用多阶段训练流程。PLM发布了两个高质量视频数据集,支持细粒度视频理解,并在多个基准测试中表现优异,推动了多模态人工智能研究。
该研究推出了一个新的行车记录仪视频数据集,包含5000个视频片段,用于汽车碰撞预测。其中3000个为无碰撞示例,2000个为有碰撞示例,涵盖多种车辆、天气和路况。基线模型在真实条件下的准确率为87%。
本研究提出了基于物理的异常检测(Phys-AD)数据集,旨在克服现有工业异常检测算法在静态数据集上的局限性。该数据集是首个大规模真实世界的物理基础视频数据集,结合物理知识和视频内容进行视觉推理,以识别物体异常。
本研究探讨了利用深度学习模型将语音转化为手势动作的方法,提出了多种生成手势的框架和模型,显著提升了手势生成的真实感和同步性。同时,研究发布了大型视频数据集,以支持模型的训练与评估。
BDD100K是最大的驾驶视频数据集,支持自主驾驶算法评估。DriveSceneGen生成高保真动态驾驶场景,DriveDreamer-2利用语言模型生成定制视频。GenAD模型通过大量数据提升预测能力,Delphi生成长视频以提高规划性能,SimGen模型结合模拟与现实数据,增强自动驾驶系统的可扩展性和安全性。
本研究探讨了视觉代理在室外场景中的导航能力,提出了多种提升导航性能的方法,包括利用大规模视频数据集和预训练模型。实验结果表明,新方法在多个基准测试中取得了显著进展,尤其在复杂环境中表现优异。
本研究提出了一种新颖的视频理解任务方法,将基于知识的问题回答融合进来,并提出了一个关于情景喜剧的视频数据集。该数据集融合了视觉、文本和时间的连贯思维,需要观看该系列影片的体验知识才能回答基于知识的问题。同时,本文提出了一种能够将视觉和文本视频内容与剧集相关的具体知识相结合的视频理解模型。主要发现是融入知识可在视频问答方面产生卓越的改进,但仍需进一步研究提高准确度。
该论文介绍了一种名为NTrack的多物体追踪系统,利用自动化追踪技术独立于检测方法,实验证明其在棉铃追踪和计数方面的有效性超过其他方法,并公开了第一个棉铃视频数据集。
该研究介绍了一个名为Cattle Visual Behaviors (CVB)的视频数据集,用于牛行为识别。通过计算机视觉标注工具(CVAT)收集了502个视频剪辑,每个剪辑15秒长,标注了11种牛的行为。使用预训练模型对视频中的牛进行检测和跟踪,并使用CVAT进行修正和标记,减少了标注时间和精力。最后,使用SlowFast动作识别模型对数据集进行训练和评估,能够准确识别牛的频繁出现的行为。
该研究介绍了一个名为REVIDE的视频数据集,包含清晰和有雾条件下的视频,同时提出了一种使用时间冗余的视频去雾算法,并使用变形金刚网络结构验证了所提出数据集的相关性。
完成下面两步后,将自动完成登录并继续当前操作。