

利用多模态大语言模型推进自我中心视频问答
Apple Machine Learning Research
·
视频流作为时间序列:发现视频问答中的时间一致性和变异性
BriefGPT - AI 论文速递
·
视频时间证据提取
BriefGPT - AI 论文速递
·

如今的智能体,已经像人一样「浏览」视频了,国内就有
机器之心
·
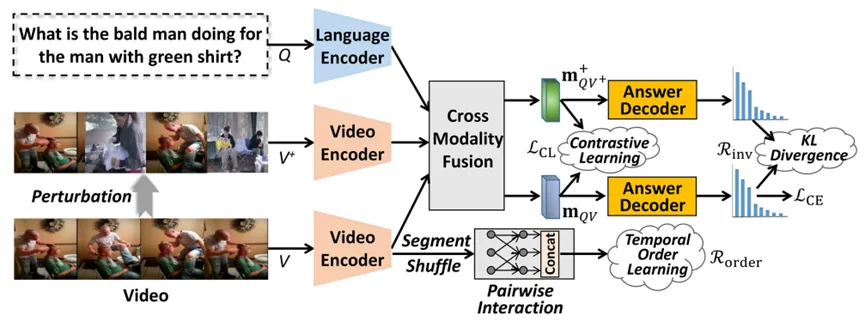
基于跨模态对比表征学习的鲁棒视频问答 | 杨勋,曾建明,汪萌等
实时互动网
·
