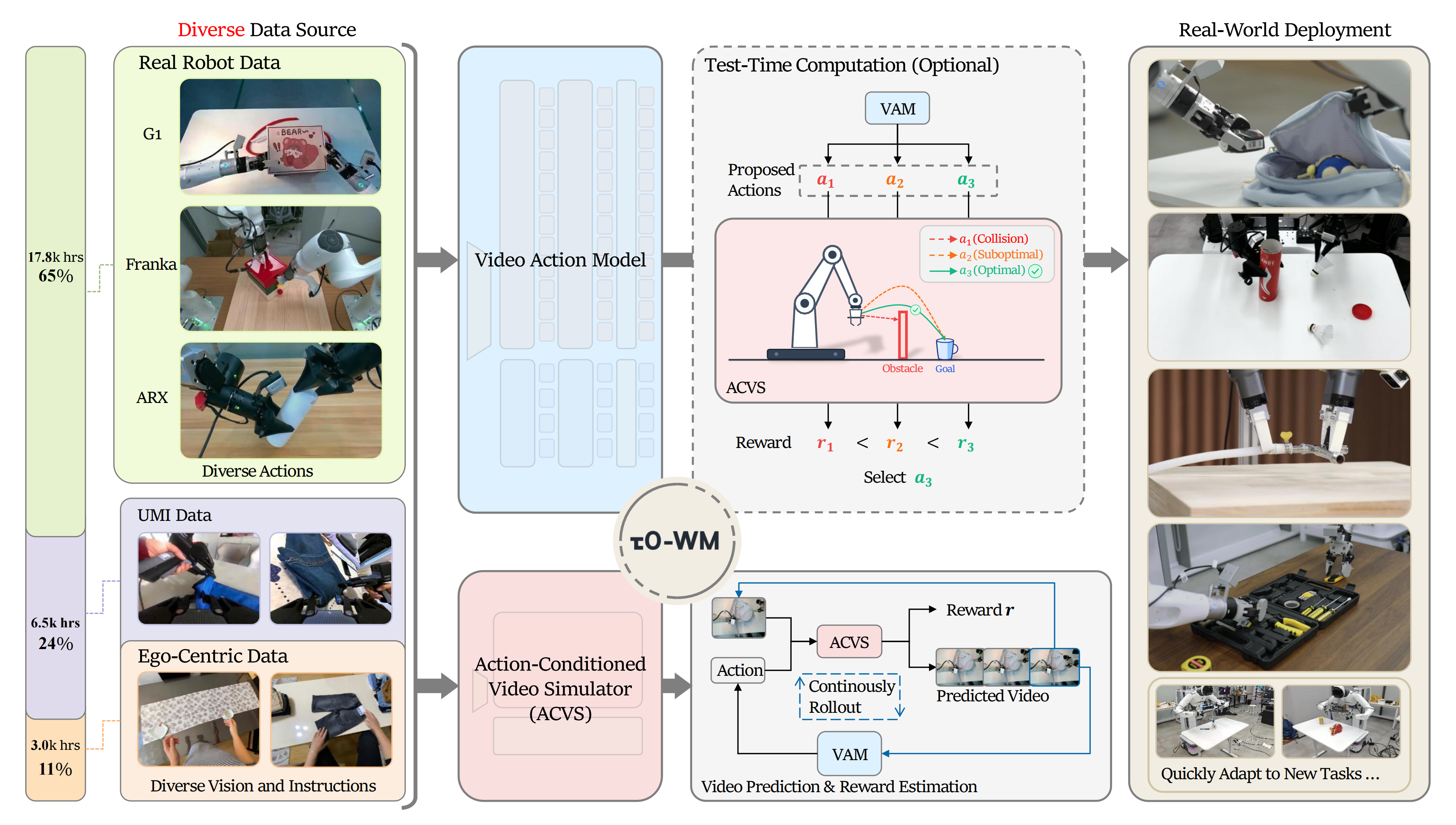
研究者提出了一种名为τ0-World Model(τ0-WM)的统一视频-动作世界模型,旨在提升机器人操作的预测能力。该模型结合视频预测、动作生成和任务评估,利用27,300小时的多样化数据进行训练。τ0-WM通过共享的预测网络,提供视频动作模型和动作条件视频模拟器两个接口,优化机器人在执行前的决策过程。
研究者探讨了世界模型代理(WAM)在测试阶段是否需要显式未来想象,提出了Fast-WAM架构,训练时保留视频共训练,推理时跳过未来预测。结果显示,视频预测主要在训练阶段提升模型性能,而非在推理阶段生成未来观测。
DreamZero是一种新型世界动作模型,通过联合预测视频和动作,提升机器人在新环境中的泛化能力。与传统模型相比,DreamZero能够高效学习多样化技能,支持零样本泛化,并实现实时控制。其核心在于利用预训练的视频扩散模型,结合自回归架构和优化策略,提高推理速度和准确性。
本研究提出了ProgGen模型,利用大型语言模型的归纳偏见,解决视频预测中动态描述模型的不足。该方法通过神经-符号的可解释状态集生成视频帧预测,尤其在复杂环境中表现优于现有技术,支持因果推理和可解释性。
本研究提出了一种新方法PVDR,利用无标注视频数据进行强化学习预训练。通过视频预测任务,基于Transformer的CVAE学习视觉动态表示,从而提高政策学习效率。实验结果表明,PVDR显著改善了视频预训练效果。
本文介绍了一种新型动作条件视频预测模型,能够模拟物体运动并推广至新对象。研究使用了59,000个机器人交互数据集,实验结果表明该模型在视频预测方面优于现有方法。此外,提出了多种基于图神经网络和动态表示的技术,提升了机器人在动态场景中的操作能力和效率。
本研究提出了一种扩展的图像扩散模型,用于高保真度视频生成,结合文本条件生成和视频预测。通过轻量级模型和新策略,优化视频质量,显著优于传统生成对抗网络。研究回顾了视频扩散模型在生成、编辑和理解任务中的应用,并探讨了未来发展趋势。
本研究提出了一种基于视频预测和深度强化学习的观察型模仿学习方法,能够从视频中学习机器人技能,如扫地和推物品。结合自然语言描述,提升了机器人在复杂环境中的操作能力。研究表明,该方法在多项任务中显著提高了成功率,并在真实世界中表现良好。
该研究提出了一种新方法“空间和时间的视频外推”,结合自我监督学习和视频预测,提升了在真实环境中的表现。通过解耦3D结构和相机姿态,该方法实现了新视角合成和相机姿态估计,展现出更高的视觉质量和准确性。
本文介绍了GazeMoDiff、Motion-Zero和MoDiff等新型运动生成模型,旨在提高视频中人体动作的预测和控制精度。这些模型结合时空特征、注意力机制和无监督学习,生成高质量、自然的运动序列,适用于虚拟现实和视频编辑任务。
本文介绍了第一个大规模自动驾驶视频预测模型GenAD,该模型通过网络数据和文本描述提升了泛化能力。在多种行驶场景中,GenAD能够生成长达25分钟的视频,并在多个数据集上取得优异成绩,展示了其在实际应用中的巨大潜力。
本文提出了一种面向视频中长期动作预测的物体中心表示,利用视觉-语言预训练模型提取特定表示。通过双重注意力网络识别人-物交互,并在多个基准测试中验证了其有效性。该模型实现了动作的同时识别和弱空间时间定位,展现了良好的性能。
本文介绍了一种新型视频预测模型,基于残差更新规则,能够有效处理复杂数据集并显著提升预测性能。该模型通过分解视频的运动和内容信息,增强了表达能力和随机性学习能力,能够在长时间范围内生成复杂场景结构和运动,预测效果优于现有方法。
V-JEPA是一种非生成式模型,通过预测视频的缺失或遮蔽部分来进行学习,提高训练和样本效率。它能够集中精力理解视频中的高层次概念信息,适应多种不同的任务。未来可能应用于具身AI研究和AR眼镜项目。
本文介绍了几种学习视频压缩的方法,包括基于空间分解和时间融合的帧间预测方法、基于联合时空相关性探索的学习型视频压缩、基于时空变换器的视频压缩框架、基于时间上下文挖掘的学习视频压缩、无监督视频分解基于时空迭代推理、通用学习视频压缩、利用基于块运动的特征插值进行视频快速语义分割、分布式编码架构的低复杂度深度视频压缩、使用多域层次约束进行深度参考生成的视频帧间预测、基于动画的视频压缩的预测编码、探究时空多频分析用于实现高保真度和时空一致性的视频预测。
本文提出了一种新的变分框架,用于推断由分数布朗运动驱动的随机微分方程。通过结合SDEs和变分方法的推断能力,使用随机梯度下降学习代表性函数分布,并使用神经网络学习变分后验中的漂移、扩散和控制项,实现了神经-SDEs的变分训练。同时,优化了Hurst指数,控制分数噪声的性质,并提出了一种用于变分潜在视频预测的新型架构。
本文提出了一种基于局部时空分离的Transformer块,用于视频未来帧预测,并构建了全自回归和非自回归视频预测Transformer框架。同时,引入对比特征损失来监督模型预测过程。该模型在性能上与更复杂的现有模型竞争力相当。
本文重新审视了视频预测中的分层模型,通过先估计语义结构序列,再通过视频到视频的转换将结构转化为像素。通过在汽车驾驶和人类舞蹈等三个数据集上的评估,证明了我们的方法能够在非常长的时间范围内生成复杂的场景结构和运动,并且取得了比现有方法长几数量级的预测时间。
完成下面两步后,将自动完成登录并继续当前操作。