


浪潮信息元脑R1深度适配SGLang最新版本
全球TMT-美通国际
·
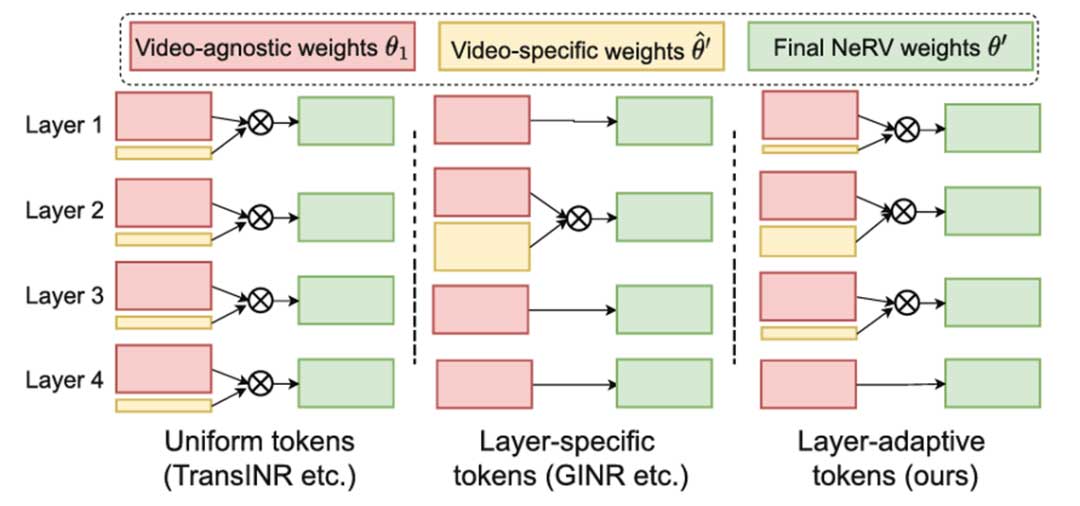
隐式视频表示的快速编码和解码 | ECCV 2024
实时互动网
·


基于Core ML的本地Llama 3.1
Apple Machine Learning Research
·
