
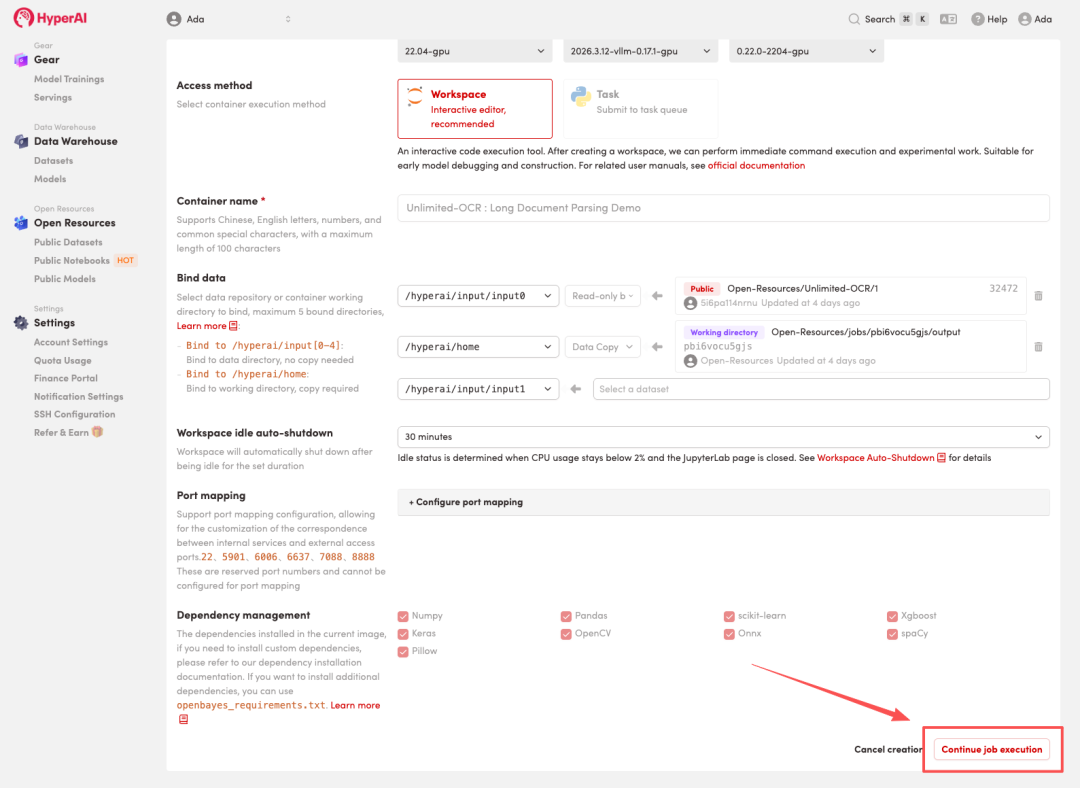
在线教程丨32K上下文一次解析数十页文档,百度开源Unlimited OCR,重构长文档复杂场景
HyperAI超神经
·

语音搜索错误纠正的音素增强判别重评分
Apple Machine Learning Research
·

研究显示,ChatGPT重度用户在识别AI生成文本方面表现出色,准确率达到76%
DEV Community
·
