本文探讨了RAG(检索增强生成)中的存储与检索层,重点介绍向量索引算法的选择和量化方法,以及2024-2026年工业界的趋势。文章分为四部分:算法底层、产品选型、工程实操和图RAG与趋势,提供实用的参数和代码示例。向量检索主要使用近似最近邻(ANN)算法,推荐HNSW作为工业标准,并结合量化技术以降低内存占用。最后,GraphRAG结合知识图谱与向量检索,提升多跳推理能力。
本研究提出了LogQuant,一种基于对数过滤机制的2位量化方法,显著提升KV缓存的内存效率和性能。在大语言模型推理中,该方法提高了吞吐量和准确性,尤其在数学和代码补全任务上,准确性改善达40%至200%。
本研究提出了一种新的即插即用KV缓存量化方法VidKV,旨在解决视频大型语言模型在处理长视频时的内存瓶颈问题。该方法将KV缓存压缩至低于2位,并通过通道级别量化实现精度与性能的平衡。
本研究提出了一种层敏感的量化方法,解决了现有方法在处理大规模神经网络时未考虑各层量化难度的问题。通过识别量化困难的层并分配更多内存预算,提出了SensiBoost和KurtBoost方法,显著提高了量化精度,在LLama模型上实现了9%的困惑度提升,仅增加2%的内存预算。
本研究提出HALO框架,解决传统量化方法在硬件适应性和效率上的不足。通过硬件感知后训练量化,优化关键路径延迟,实现动态频率调整。研究表明,HALO在TPU和GPU上平均提升性能270%,节省51%能量,同时保持稳定精度。
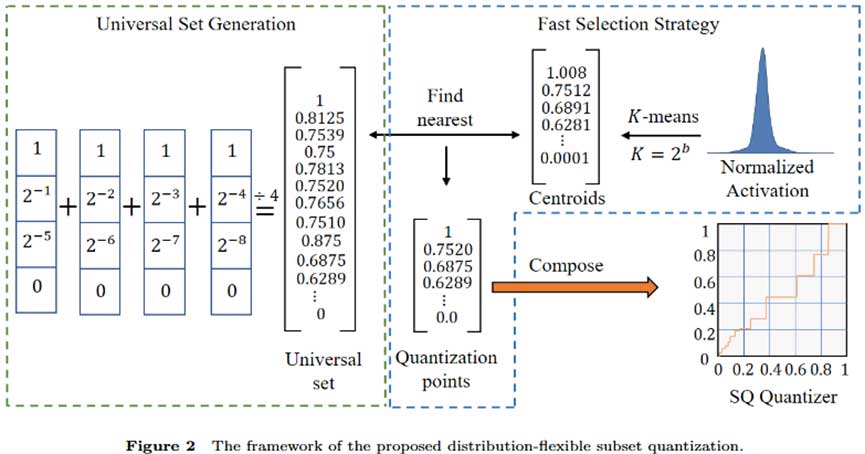
图像超分辨率(SR)技术旨在从低分辨率图像恢复高分辨率图像,但现有模型在资源受限设备上部署困难。本文提出了一种分布灵活的子集量化方法(DFSQ),通过归一化和快速量化点选择,显著提高了计算效率,尤其在低比特情况下表现优异,验证了其有效性。
本研究探讨大型语言模型的记忆现象及其隐私和安全风险。通过分析记忆与训练时长、数据集规模和样本相似性的关系,提出量化方法,并为降低风险提供理论和实证支持。
本文提出了一种新颖的混合精度量化方法,旨在提高语音基础模型的量化效率。该方法结合了混合精度学习与模型参数估计,显著提升了压缩比,缩短了压缩时间,同时保持了单词错误率不变,展现了良好的实际应用前景。
本文介绍了一种量化方法,旨在提升大语言模型(LLM)在服务器上的推理效率。该方法将通信特征值从16位降低至4.2位,同时几乎保持原有性能,Gemma 2 27B和Llama 2 13B的性能分别为98.0%和99.5%。
该研究提出了一种新方法,将服务器大型语言模型推理中的通信成本从16位降低至4.2位,同时保持约98.0%和99.5%的原始性能,显示出显著的应用潜力。
本研究分析了卡尔德隆·德·拉·巴尔卡喜剧中的性别描绘,运用量化方法和性别分类器对100多部作品进行研究,结果显示男女角色描绘存在显著差异,模型在不同场景中对变装角色的预测具有文化分析价值。
本研究提出了一种基于嵌套晶格的量化方法,解决了矩阵乘法加速中的不足,明确了近似误差,并在高斯矩阵下达到了下界,证明其渐近最优。这为提升大语言模型的矩阵乘法性能提供了理论支持。
本文介绍了一种新型的H3 SSM层和FlashConv技术,旨在提高语言模型的训练效率和性能。研究表明,选择性状态空间模型(SSMs)在多项任务上超越了传统Transformer,尤其在长序列推理中表现优异。此外,提出的量化方法有效降低了模型部署成本,同时保持了准确性,为大语言模型的高效应用提供了新思路。
本研究提出了多种深度神经网络的量化方法,旨在提高计算效率和模型性能。通过端到端深度强化学习框架和自适应量化技术,保持高准确性并降低计算成本。新方法如HAWQ、SAT和GPTQ等在不同模型上表现优于传统方法,推动了神经网络在资源受限环境中的应用。
本文提出了多种针对扩散变换器(DiTs)的量化方法,包括EfficientDM、PTQ4DiT和VQ4DiT。这些方法通过量化感知训练和后训练量化技术,在保持图像生成质量的同时,显著降低了计算成本和模型大小,适用于边缘设备的高效推理。
本文探讨了机器学习中的不确定性,区分了确立不确定性和偶发不确定性,并提出了新的不确定性量化方法。研究表明,显式考虑不确定性可以提升模型性能,强调了贝叶斯方法与证据深度学习的应用。实验结果揭示了不同不确定性估计器的表现,为未来研究提供了指导。
本文介绍了多种神经网络量化方法,如阈值训练、梯度量化和自适应无数据量化。研究表明,量化能够在保持精度的同时提高模型效率,尤其适用于资源受限环境。提出的AdaQAT方法在训练过程中自动优化比特宽度,表现出色,具有竞争力。
本文介绍了使用半精度浮点数训练深度神经网络的技术,显著提高了计算速度并减少了内存消耗。实验表明,该方法在多个数据集上性能优于传统精度。还探讨了混合精度框架的优化技巧及其对模型训练的影响,并提出了新的量化方法以提高推理效率。
本研究提出了一种新型隐私保护量化方法RQP-SGD,结合差分隐私与随机量化,旨在高效、安全地处理物联网设备的数据。研究探讨了随机化技术对深度神经网络的影响,发现噪音和随机掩码有助于减少过拟合。通过超参数优化,评估了多种数据集的性能,结果显示数据增强和权重初始化对性能影响显著。此外,提出了新的权重初始化方法和优化RNN模型的方案,展示了在低功耗硬件上训练的潜力。
本文介绍了多种针对大型语言模型的量化方法,如LR-QAT、QLLM和RPTQ,旨在提高计算效率和降低存储需求。这些方法通过低秩辅助权重和激活量化感知等技术,在保持预测性能的同时,实现了显著的内存节省和加速,推动了大型语言模型的实际应用。
完成下面两步后,将自动完成登录并继续当前操作。