CSS锚点定位是一项强大的新特性,Chrome 143+支持回退检测,允许在容器类型为anchored时自动调整位置。通过设置position-try-fallbacks属性,可以实现提示框在触碰浏览器边缘时垂直翻转的效果。尽管该特性尚不广泛兼容,但为开发者提供了新的可能性。
本研究解决了现实机器学习应用中的分布转移和标签噪声问题,现有模型通常过分关注冗余特征,导致泛化能力差。提出的锚点对齐和自适应加权方法(A3W)通过自然语言处理锚点重新加权样本,从而提取更具代表性的特征,使模型对噪声标签更具鲁棒性。实验证明,A3W在多个数据集上表现优于现有领域泛化最佳方法,显著提高了准确性和鲁棒性。
本研究解决了RNA分子设计中与特定蛋白质相互作用的挑战,提出了一种深度学习模型RNA-BAnG,能够在没有大量实验确定的RNA序列或对RNA结构深入了解的情况下生成RNA序列。通过双向锚定生成的创新方法,该模型显示出在生物序列的条件RNA序列设计中的有效性,具有显著的潜在影响。
AIxiv专栏促进学术交流,报道超过2000篇文章。淘天集团未来生活实验室专注于大模型和多模态AI技术,提出令牌级偏好对齐方法(TPO),有效缓解视觉大模型的幻觉现象,提升模型与视觉信息的关联性。
本研究探讨了大型语言模型中的锚定偏差,发现初始信息对判断有显著影响。实验验证了缓解策略的有效性,强调全面收集信息以避免模型被单一信息锚定的重要性。
2024年被称为“大模型应用元年”,科大讯飞推出星火4.0 Turbo,超越GPT-4 Turbo,推动教育和医疗等领域的AI应用。新发布的高中数学智能教师系统和AI作业过滤器提升学习效率,医疗大模型助力智慧医院建设。科大讯飞还与多个行业合作,推动大模型落地,满足多元需求。
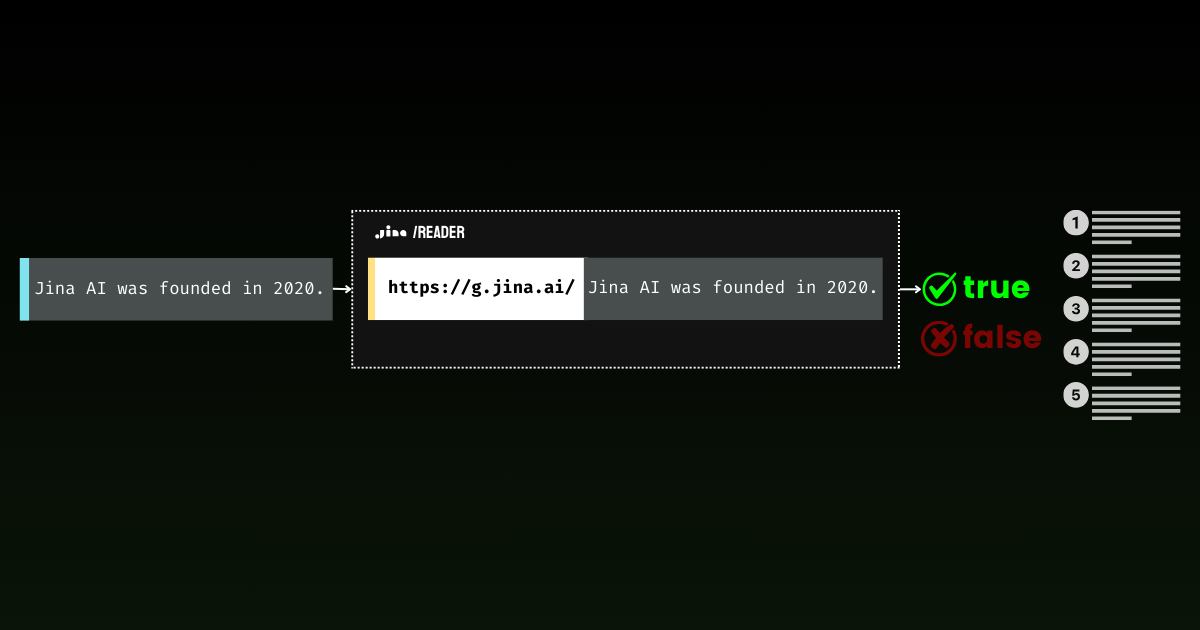
文章强调“锚定”在生成式AI中的重要性,特别是防止大语言模型产生错误信息。Jina AI开发了g.jina.ai API,通过实时网络搜索提供事实支持,并返回准确性评分。尽管存在高延迟和依赖网络数据质量的限制,该API在研究和政治讨论中提供实时事实核查。未来计划包括整合私人数据源和提升多跳问答能力。
CodeUltraFeedback是一个包含10,000个复杂指令的偏好数据集,用于调整和对齐语言模型与编码偏好。通过使用CodeUltraFeedback的AI反馈数据,CodeLlama-7B-Instruct在CODAL-Bench上优于34B模型。经过优化的CodeLlama模型在HumanEval+上的功能正确性有所改进。这项研究为语言模型对编码偏好的调整和代码智能的发展奠定了基础。
本研究提出了历史增强锚定变压器(HAT)框架,解决了在线视频理解中忽略历史信息的问题。实验证明,该模型在程序性自我中心数据集上超越了最先进的方法,显示了利用长期历史信息的重要性。
本文介绍了一种名为Context-I2W的新型网络,用于将图像信息转换为描述的伪词标记,以实现准确的零样本组合图像检索任务。该网络通过学习旋转规则将相同图像映射到特定任务的操作视图,并捕获涵盖主要目标的局部信息,无需额外监督。该模型在四个零样本组合图像检索任务上表现出很强的泛化能力,并取得了新的最先进结果。
通过引入因果正则化扩展到锚定回归(AR)来改善超出分布的广义。提出与锚定框架一致的锚定兼容损失,以确保对分布变化的鲁棒性。各种多变量分析(MVA)算法适用于锚定框架。锚定正则化的通用性凸显了其与 MVA 方法的兼容性,并在增强可复制性的同时防范了分布变化。扩展的 AR 框架推进了因果推断方法,解决了可靠的超出分布广义化的需求。
该论文介绍了一种解决低资源场景下关系抽取的方法,通过自监督学习和对比学习进行预训练和微调。实验证明该方法在使用1%数据时,性能提高了10.5%和5.8%。
本文提出了一种新的方法,通过将地理参考维基百科文章与其对应位置的卫星图像配对构建名为 WikiSatNet 的新型数据集,并提出了两种学习卫星图像表示的策略。在最新发布的 fMoW 数据集上,本文的预训练策略可以将在 ImageNet 预训练的模型的 F1 分数提高 4.5%。
用户严重依赖他们看到的第一条信息。 用户获得的初始信息会影响后续的判断。即使目标性质与手头的决定没有任何关系,锚定目标通常也会起作用。增加感知价值很有用。 当人们试图做出一个决定时,他们经常使用一个锚或焦点作为参考或起点。心理学家发现,人们有一种倾向,即过于依赖他们所了解的第一条信息,这可能对他们最终作出的决定产生严重影响。 ...
完成下面两步后,将自动完成登录并继续当前操作。