


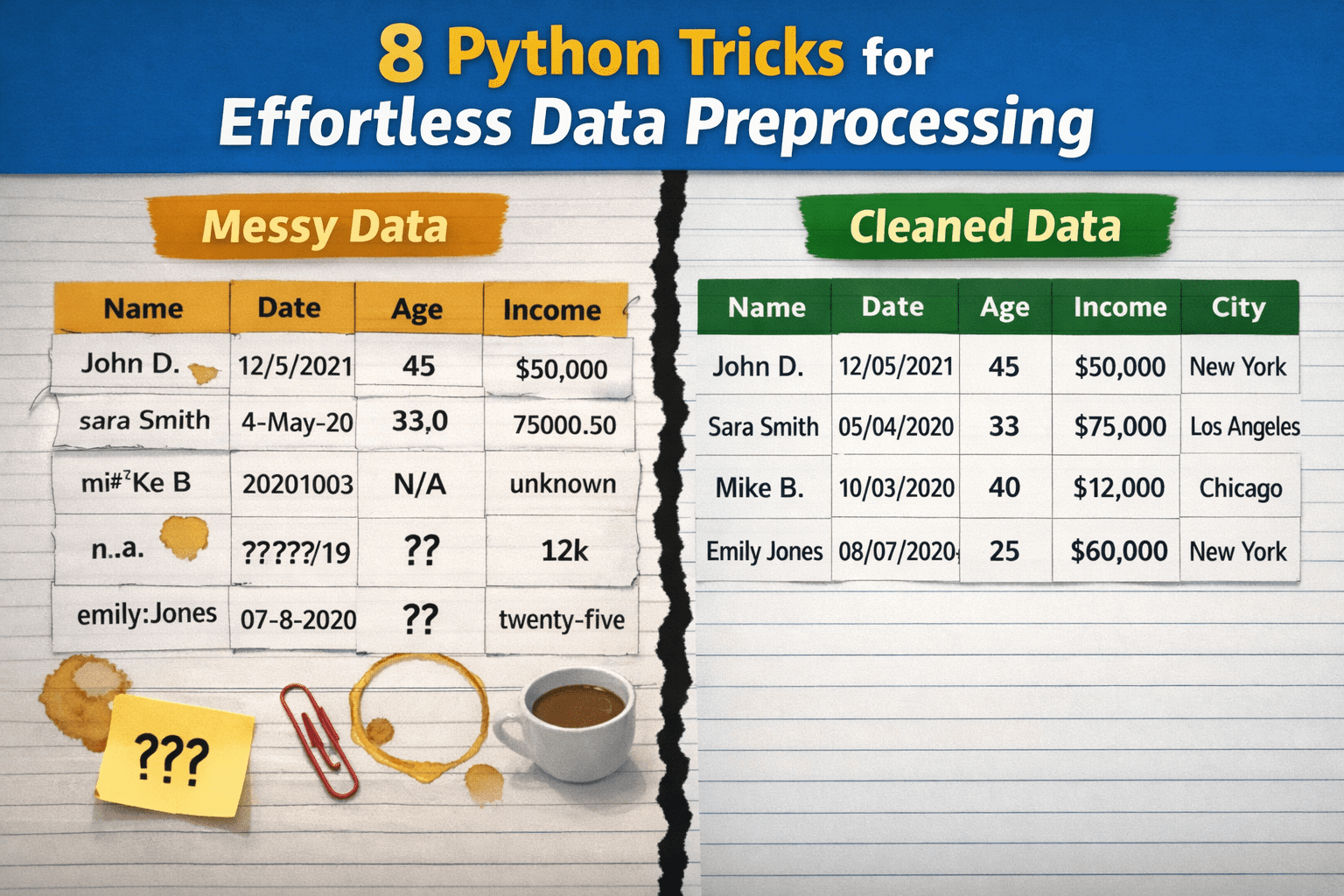
从混乱到整洁:8个轻松的数据预处理Python技巧
KDnuggets
·

您的机器学习管道效率是否达到最佳?
KDnuggets
·

等离子预处理与去氧化技术协同应用,革新功率模块生产
全球TMT-美通国际
·

文本到视频模型的训练数据预处理
InfoQ
·

尼古拉·萨莫赫瓦洛夫:#PostgresMarathon 2-008:LWLock:锁管理器与预处理语句
Planet PostgreSQL
·



数据预处理笔记(sklearn)
子虚栈
·

数据预处理笔记(sklearn)
子虚栈
·

第1部分:利用EEG和深度学习检测阿尔茨海默病——理论、动机与预处理
DEV Community
·
