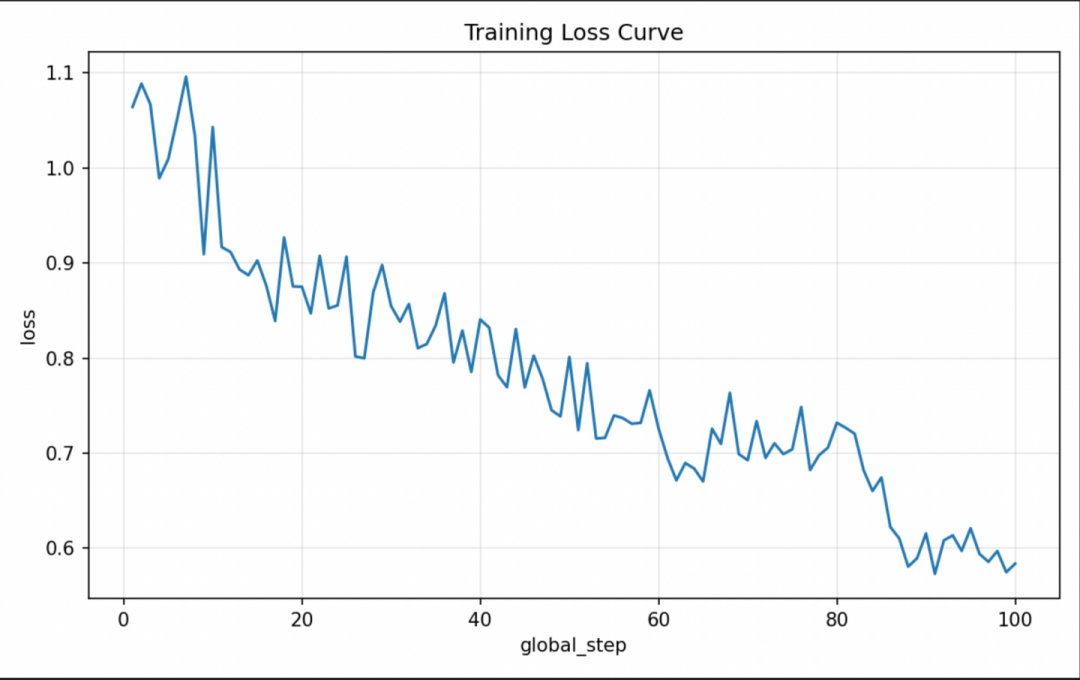
近期,基于PaddleFormers v1.0,在昆仑芯P800上成功完成DeepSeek-V3模型的全参数微调,验证了超大规模模型的可控性及优化训练效率。通过混合并行训练策略和多硬件算子验证工具,显著提升了算力利用效率,并总结了显存管理、长序列输入处理及负载均衡等关键技术,为未来大规模模型训练提供了参考。
机器之心数据服务现已上线,提供高效稳定的数据获取,简化数据爬取流程。
机器之心数据服务现已上线,提供高效稳定的数据获取服务,简化数据爬取流程。
DeepSeek推出的Prover-V2模型专注于数学定理证明,刷新多项基准测试记录。该7B模型成功解决了671B模型未能解决的问题,展现出独特的推理模式。Prover-V2结合强化学习与子目标分解,提升了形式化与非形式化证明的能力,标志着数学领域的重要进展。
本文介绍了DeepSeek大模型的部署过程,包括硬件需求、驱动安装、基础环境配置、模型拉取及运行等步骤。强调显存和内存配置对模型性能的重要性,并提供了具体的命令和配置文件示例,同时讨论了可能遇到的性能问题及其解决方案。
字节推出的Seed-Thinking-v1.5模型以200B参数超越DeepSeek-R1的671B,提升了推理表现。通过优化数据和强化学习算法,该模型在数学和代码等任务中表现优异。尽管在某些基准测试中仍落后于o3-mini-high,但其潜力引发关注。
香港大学与华为诺亚方舟实验室推出了扩散推理模型Dream 7B,突破了自回归与扩散模型在生成任务中的界限。该模型在通用能力、数学推理和编程任务上表现优异,展示了扩散建模在自然语言处理中的潜力。研究团队将发布模型权重,并将继续优化扩散语言模型。
上海财经大学团队发布了金融大语言模型Fin-R1,参数为7B,性能超越同规模模型,平均得分75.2,接近671B的DeepSeek-R1。该模型通过构建60k条高质量金融推理数据集,并结合指令微调和强化学习,提升了金融领域的推理能力,展现出卓越的适应能力。
私有化部署大模型可有效保护数据隐私,本文探讨DeepSeek大模型的纯CPU部署,成本约3.8万元,使用llama.cpp框架,q8精度下实现7.17 tokens/s的输出速度。通过散热改进和系统优化,长文本生成速度提升约25%。文章包括装机选型、软硬件配置和性能测试三部分,提供详细配置建议和测试结果。
阿里巴巴通义千问团队开源了QwQ-32B模型,参数320亿,性能接近6710亿参数的DeepSeek-R1。该模型通过强化学习提升推理能力,支持批判性思考,尤其在数学推理和代码编写方面表现优异,已在Apache 2.0许可证下开源。
DeepSeek推出的671B开源模型显著改变了AI市场,尤其对B端用户影响深远。OpenAI因流量压力计划推出GPT-5并调整商业模式,提供免费功能吸引用户。百度文心一言也转向免费开源,面临广告收入挑战。未来AI盈利模式仍需探索。
问小白推出了DeepSeek-R1 671B满血版,强调不卡顿、零延迟和全免费。该App支持联网搜索和语音输入,提供快速、精准的搜索体验,用户可随时使用。
通义灵码是阿里云与通义实验室合作开发的智能编码助手,支持200多种编程语言,兼容VS Code和JetBrains IDEs,具备智能补全、自然语言生成代码和智能问答等功能,帮助开发者高效编码。新模型选择功能允许用户根据需求切换模型,降低AI编程技术门槛。
潞晨云推出“满血DeepSeek-671B-R1/V3解决方案”,提供免费通道、无代码使用和VIP通道,适合各类用户。支持联网搜索,提升回答准确性,企业级API价格低于官方,满足高性能需求。
自DeepSeek R1发布以来,其强大性能引发广泛关注,导致官网服务器负担加重。为应对这一挑战,硅基流动与华为云联合推出基于昇腾云的DeepSeek R1 & V3推理服务,标志着国产GPU替代英伟达GPU的重要进展。此次合作有望改善国产GPU的适配性问题。
AIxiv专栏促进学术交流,报道超过2000篇内容。DeepSeek R1模型通过动态量化技术实现本地部署,降低硬件要求。作者提供详细的部署步骤和测试结果,建议在消费级硬件上进行轻量任务。
DeepSeek V3模型发布,参数量671B,训练成本仅557.6万美元,算力消耗为Llama 3的1/11。性能超越多款顶尖模型,生成速度提升3倍,API价格大幅降低,完全开源,支持FP8和BF16推理,受到广泛关注与测试。
国产大模型DeepSeek-V3以671B参数和278.8万H800 GPU小时的训练成本,表现优异,超越多款开源模型。其MLA和DeepSeekMoE架构提升了推理效率,标志着分布式推理新时代的到来。
完成下面两步后,将自动完成登录并继续当前操作。