
PaddleFormers驱动:最少国产算力完成DeepSeek-V3(671B)全参数微调实践
内容提要
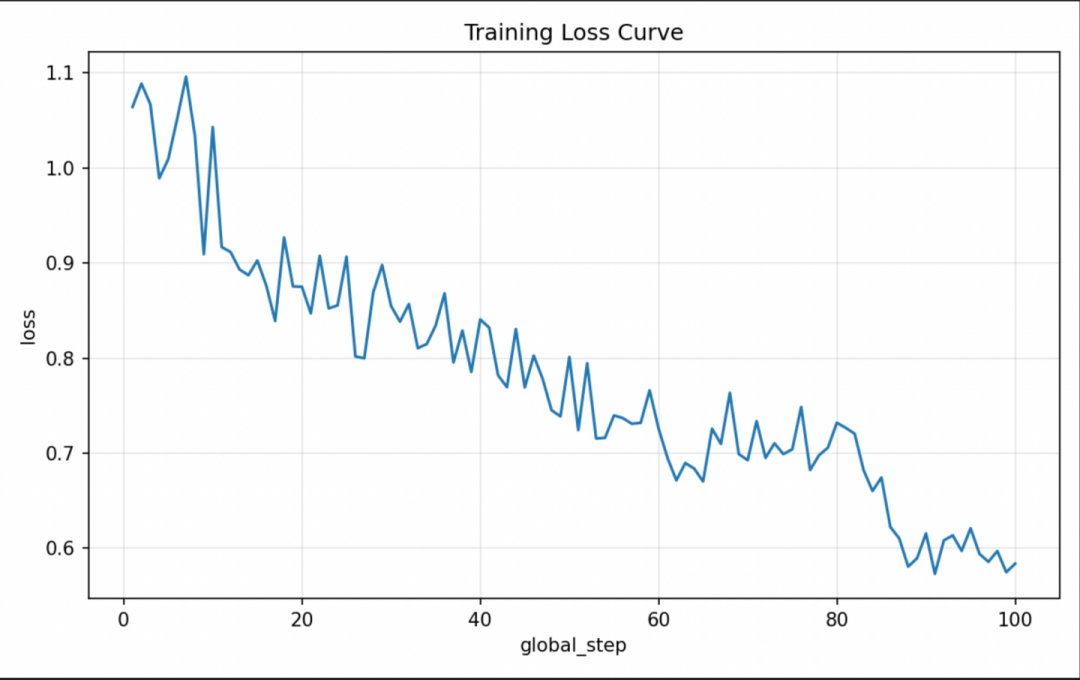
近期,基于PaddleFormers v1.0,在昆仑芯P800上成功完成DeepSeek-V3模型的全参数微调,验证了超大规模模型的可控性及优化训练效率。通过混合并行训练策略和多硬件算子验证工具,显著提升了算力利用效率,并总结了显存管理、长序列输入处理及负载均衡等关键技术,为未来大规模模型训练提供了参考。
关键要点
-
基于PaddleFormers v1.0,在128卡昆仑芯P800上成功完成DeepSeek-V3模型的全参数微调实验。
-
此次实践验证了超大规模模型在特定业务场景中的可控性与实际落地能力。
-
采用混合并行训练策略,整合多种并行训练技术,显著提升了算力利用效率。
-
引入PaddleAPITest多硬件算子验证工具,提升了适配效率和验证结果的准确性。
-
在大规模参数训练中,采用Offload技术解决显存问题,确保训练任务的持续运行。
-
引入Subbatch方法应对长序列输入训练中的显存挑战,有效节省显存空间。
-
合理引入负载均衡与优化技巧,确保MoE模型训练过程的稳定性与准确性。
-
本次实践为未来大规模模型训练技术的发展提供了有力的参考和借鉴。
延伸解读
超大规模模型的可控性
此次实践验证了DeepSeek-V3模型在特定业务场景中的可控性,表明超大规模模型不仅具备强大的计算能力,还能在实际应用中有效落地。这为未来在行业中的广泛应用奠定了基础,尤其是在需要处理复杂数据的领域。
显存管理的重要性
在大规模模型训练中,显存管理是一个关键挑战。通过引入Offload技术和Subbatch方法,能够有效解决显存不足的问题,确保训练过程的稳定性。这些技术的应用为其他开发者在类似场景下提供了宝贵的经验和解决方案。
混合并行训练策略的优势
采用混合并行训练策略,整合多种并行技术,显著提升了算力利用效率。这种方法不仅降低了对算力资源的需求,还为大规模模型的训练提供了更高效的解决方案,值得其他研究者借鉴。
延伸问答
DeepSeek-V3模型的全参数微调实验使用了什么硬件?
实验使用了128卡昆仑芯P800硬件。
在DeepSeek-V3的微调过程中采用了哪些技术来提升算力利用效率?
采用了混合并行训练策略,整合了多种并行训练技术,如Sharding并行、流水线并行等。
如何解决大规模参数训练中的显存问题?
采用Offload技术,将部分优化器状态从显存转移到内存中,以确保训练任务的持续运行。
PaddleAPITest工具在实验中起到了什么作用?
PaddleAPITest工具确保模型在多硬件设备上达到理想的收敛状态,并提升了适配效率和验证结果的准确性。
在长序列输入训练中,如何应对显存挑战?
引入Subbatch方法,将长序列输入分割成多个子批次进行计算,有效节省显存空间。
本次实验对未来大规模模型训练有什么参考价值?
本次实践总结了显存管理、长序列输入处理及负载均衡等关键技术,为未来大规模模型训练提供了有力的参考和借鉴。
