CnOCR V2.3 新版发布,模型都经过了重新训练和精调,精度比旧版模型更高。同时加入了分场景、大小规模不同的各种模型,可商用。
CnOCR V2.3 版本发布,经过重新训练和精调,精度更高。新增多种场景和规模的模型,支持简体中文、英文及数字识别。模型分为场景、文档、数字和通用四类,满足不同应用需求。用户可在在线 Demo 验证效果,模型可免费获取或购买。
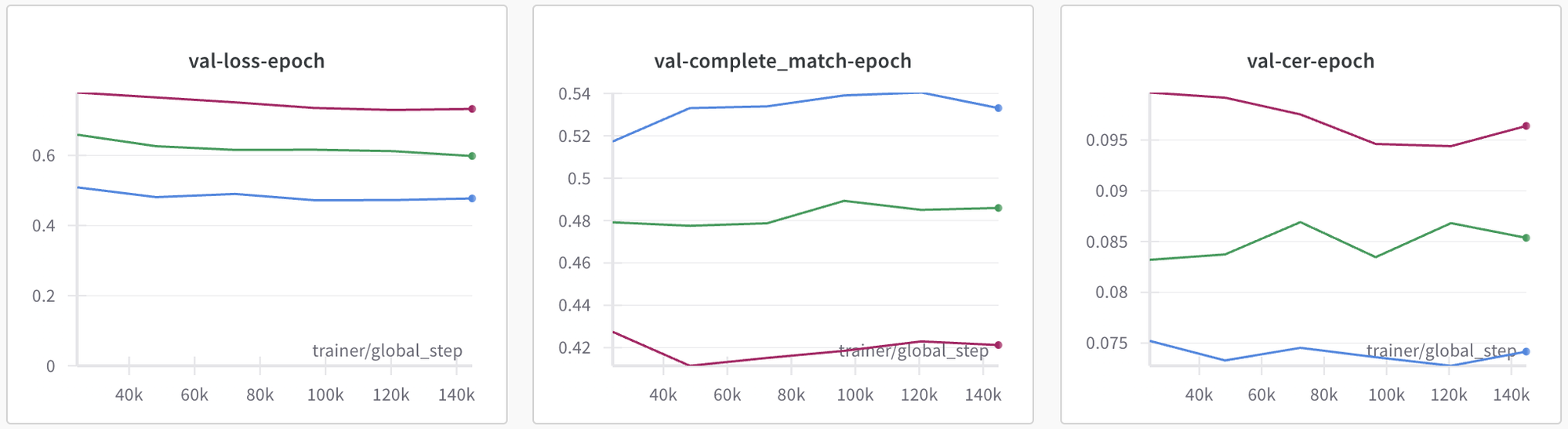
CnOCR训练了一系列新的纯数字识别模型,包括densenet_lite_136-fc、densenet_lite_136-gru和densenet_lite_666-gru_large。模型可在线或离线使用,其中number-densenet_lite_136-fc可免费下载,number-densenet_lite_136-gru仅限星球会员免费使用,number-densenet_lite_666-gru_large需购买。
CnOCR是一个中英文OCR开源工具,最新的V2.3版本经过精调,支持多种场景和语言,适合商业使用。用户可通过HuggingFace或ModelScope访问在线演示,模型可从Github或Gitee下载。
CnOCR是一个开源的中英文OCR工具,最新版本V2.3于2023年发布,支持多种行业模型和在线演示,具备数字识别能力,用户可通过HuggingFace或ModelScope访问,模型可用于商业用途。
本内容仅限知识星球 CnOCR/CnSTD/P2T私享群 会员专享。内容为 CnOCR 中关于自己训练识别模型的详细介绍。大家可以从零开始训练自己的模型,也可以基于CnOCR开源的模型进行精调。
本文详细介绍了CnOCR识别模型的训练教程,包括准备工作、训练命令、步骤、数据准备和模型调用,适合希望从零开始学习OCR技术的读者。
完成下面两步后,将自动完成登录并继续当前操作。