本研究提出DualReal框架,解决视频定制中的身份与运动冲突问题。通过动态选择训练和去噪阶段,有效融合身份与运动模式,实验结果表明其在多个评估指标上优于现有方法,推动视频生成技术的发展。
本研究提出了一种以用户为中心的人工智能模型定制方法,旨在解决黑箱AI在高风险领域缺乏用户控制的问题。通过重新设计的Rhino-Cyt平台,用户可以干预AI决策过程,优化预测,促进人机协作与解释驱动的用户干预。
本研究发布了FaceID-6M,这是首个包含600万对高质量文本-图像配对的开源人脸识别数据集。基于该数据集训练的模型性能与现有工业模型相当,甚至有所提升。
本研究提出了UASTrack框架,解决了现有RGB-X跟踪器在单一目标跟踪中对模态自适应感知关注不足的问题。通过Discriminative Auto-Selector和Task-Customized Optimization Adapter,该框架显著提升了跟踪性能,且训练参数极少,具有广泛的实际应用潜力。
本研究提出了一种新工具,能够自动生成和定制事实表,解决了现有工具在数据语义理解和用户需求对接方面的不足。该工具利用协作AI工作者,将原始表格数据转化为视觉吸引力强的事实表,用户可通过自然语言指令进行调整,从而提升用户体验。
该研究提出了AttentionSmithy,一个模块化软件包,旨在简化变压器架构的定制,帮助缺乏低级实现专业知识的领域专家快速原型化和评估变压器变体,从而加速研究进展。
本研究提出了CharacterBench基准测试,旨在全面评估大型语言模型的角色定制能力。该基准涵盖25个角色类别和22,859个样本,通过定义11个评估维度和开发CharacterJudge模型,提高了评估的效率和稳定性,实验结果显示其在角色定制能力上具有显著优势。
本研究提出了LoRACLR方法,解决个性化模型合并中的属性缠结问题。该方法能够无缝整合多个LoRA模型,提升个性化图像生成能力,无需单独微调。研究结果表明,LoRACLR在准确合并多个概念方面表现优异。
本研究提出了一种新方法DECOR,解决了文本到图像模型在有限参考图像下的过拟合问题,显著提高了定制效果和文本与图像的对齐性能,实验结果优于现有模型。
该研究提出了任务导向自适应调节(T-OAR)机制和任务相关动态提示注入(T-DPI)模块,以解决红外与可见图像融合在多任务处理中的复杂性和性能下降问题。这些方法在对象检测、语义分割和显著性目标检测等任务中表现优异,提升了图像融合的效率与适应性。
本文探讨了如何定制AWS Bedrock模型以满足特定需求,优化吞吐量和管理成本。讨论了微调和持续预训练作为个性化方法,Bedrock的吞吐量选项和定价模型。还将微调与RAG方法进行了比较,并提供了优化Bedrock使用的技巧。文章强调了Bedrock构建生成式AI应用的强大能力。
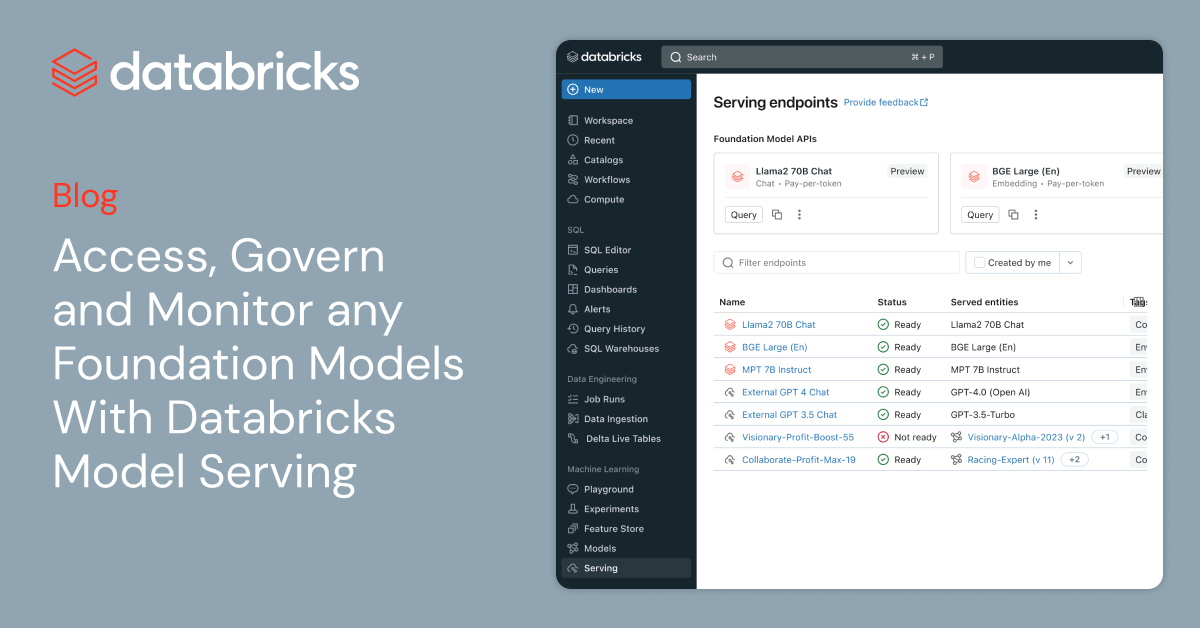
Databricks推出了Model Serving平台的重大更新,提供了一个统一的界面,可以跨所有云和提供商管理和查询基础模型。新界面使用户更容易地进行实验、定制和生产化模型。Databricks Model Serving支持Databricks管理的模型和外部托管的第三方模型。该平台还提供Foundation Model API,以便立即访问流行的基础模型,并提供按需定价选项。此外,Databricks还在其市场中添加了经过策划的基础模型。该平台旨在简化查询、管理和监控基础模型的过程,并允许使用私有数据进行定制。用户可以使用Databricks AI Playground开始尝试生成式AI模型。
完成下面两步后,将自动完成登录并继续当前操作。