地理空间优化在城市建设中至关重要,传统方法存在局限。梁浩健博士在学术年会上介绍了基于分层深度强化学习的城市应急消防设施配置优化研究,提出了动态覆盖注意力模型和自适应交互注意力模型,提升了布局效率和风险评估精度。未来将结合地理信息系统与深度学习,探索更复杂的优化问题。
本研究提出了一种双层代理系统(TTA),旨在提升《街头霸王 II》游戏的玩家体验。实验结果显示,该系统在多样性和技能水平方面显著改善了玩家的乐趣,反馈证实了其有效性。
深度强化学习(DRL)在AI中快速发展,应用于自动驾驶、游戏和金融等领域。它结合深度学习和强化学习,通过试错法优化决策。学习DRL需掌握AI和机器学习基础,并使用工具如TensorFlow、PyTorch和OpenAI Gym。DRL在Web5中也有潜力,值得探索。
本研究解决了形态变换四旋翼飞行控制设计的复杂性问题,因其难以建立准确的数学模型。论文提出了一种新的凸组合深度强化学习(cc-DRL)算法,结合了无模型控制和凸组合技术,能够有效优化四旋翼的飞行控制。仿真结果表明,该算法在提升飞行性能方面具有显著潜力。
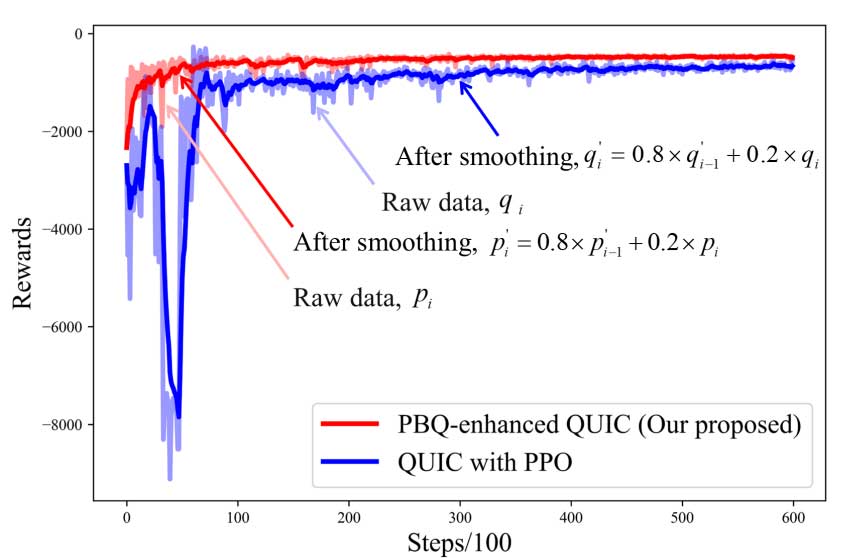
该团队提出了一种高效的拥塞控制机制PBQ-Enhanced QUIC,结合了PPO和BBR算法,实验结果显示其在吞吐量和RTT方面优于现有的QUIC版本。该机制利用DRL的环境感知和决策优势,提高拥塞控制算法的效率。
本研究利用深度强化学习技术优化期权定价和行权策略,C51算法实现了8%的超额回报。研究还探讨了分布强化学习中的分位回归及其算法,提出了新型动态对冲模型,并结合Black-Litterman模型提升投资组合回报,展示了深度强化学习在金融领域的有效性和潜力。
本文探讨了深度强化学习中的鲁棒性提升方法,包括通过平滑性正则化提高策略的抗扰动能力和使用对抗训练增强分类器效果。研究表明,这些新方法在多种攻击下提高了算法的鲁棒性和样本效率,并在多个基准测试中表现优异。
本文提出了一种基于知识辅助的深度强化学习算法,用于设计5G移动通信网络中的无线调度器。该算法结合在线和离线学习,显著提高了收敛速度和QoS性能,减少了30%~50%的数据包丢失率。实验结果表明,该方法在调度和资源分配方面优于现有方案,具有良好的应用前景。
本文介绍了一种使用深度强化学习的先进技术,用于监测有交通的桥梁的结构健康。该技术利用边缘检测技术对裂缝进行检测和定位,并评估了边缘检测和卷积神经网络在损伤检测方面的优劣。实验结果表明该方法有效。
研究人员成功将现代AI模型与几何形式系统整合,建立了一个完整且兼容的平面几何形式系统。他们提出了几何形式化理论(GFT),构建了包含88个几何谓词和196个定理的形式系统,并开发了形式几何问题解决器(FGPS)。实验证明GFT的正确性和实用性。
本文提出了一种基于反射模式调制的RIS增强的多输入单输出系统,通过优化问题和交替优化技术提出了一种高质量的子优化解决方案。研究表明该方案在可达速率性能方面优于传统的无信息传输的RIS协助系统。
本文介绍了使用回归模型学习QoS和资源分配关系的方法,利用强化学习代理进行动态缩放截片资源以维持所需的QoS水平和提高资源效率。该方法具有鲁棒性和在不同流量模式下推广的性质。结果表明,该方法能够在未见的流量上保持QoS降级在10%以下,同时最小化资源分配,并展示了对不同网络条件和不准确流量预测的鲁棒性。
完成下面两步后,将自动完成登录并继续当前操作。