

使用 Amazon S3 Tables 优化数据湖:从Hudi 迁移到托管 Iceberg
亚马逊AWS官方博客
·
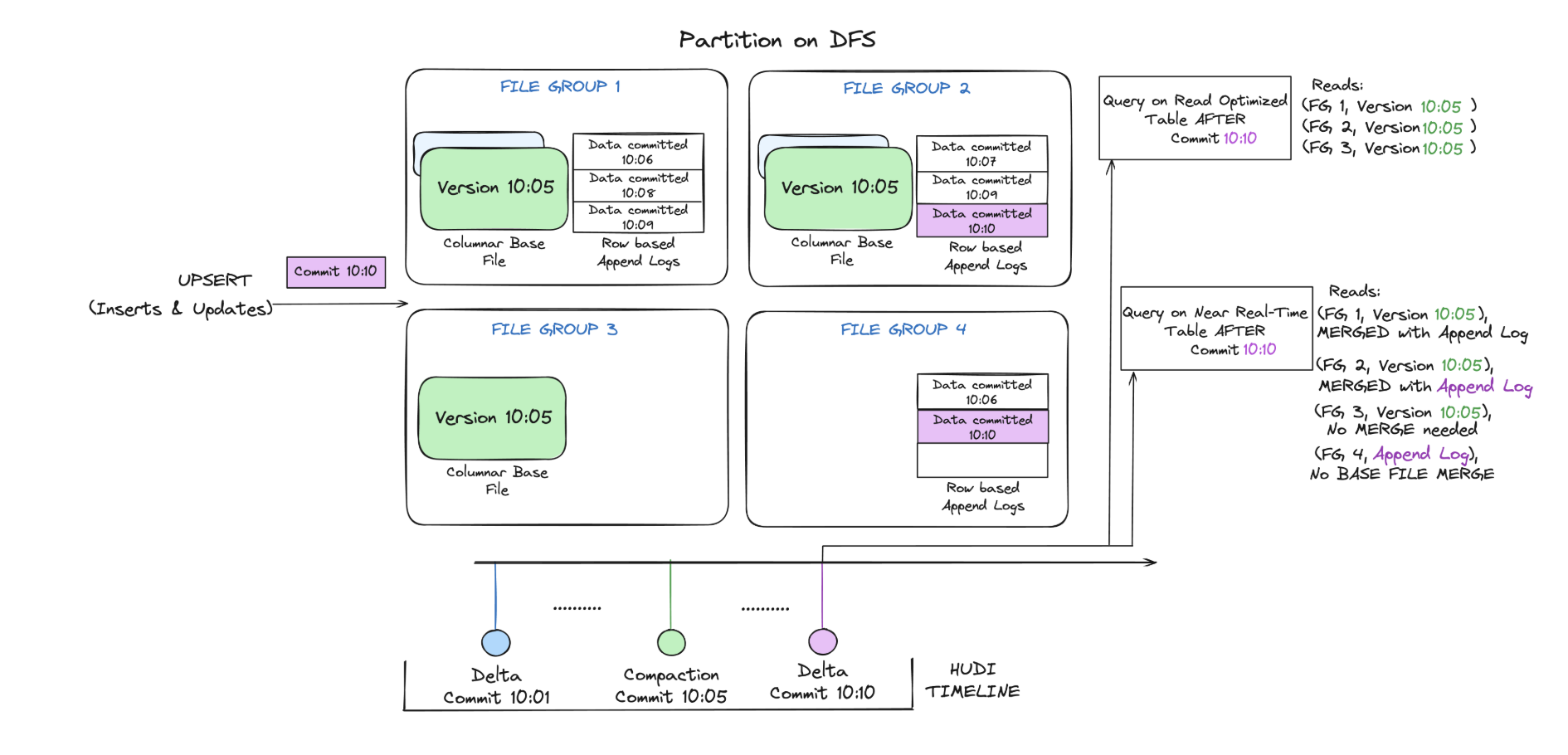
Hudi系列:表类型(Table & Query Types)
京东科技开发者
·
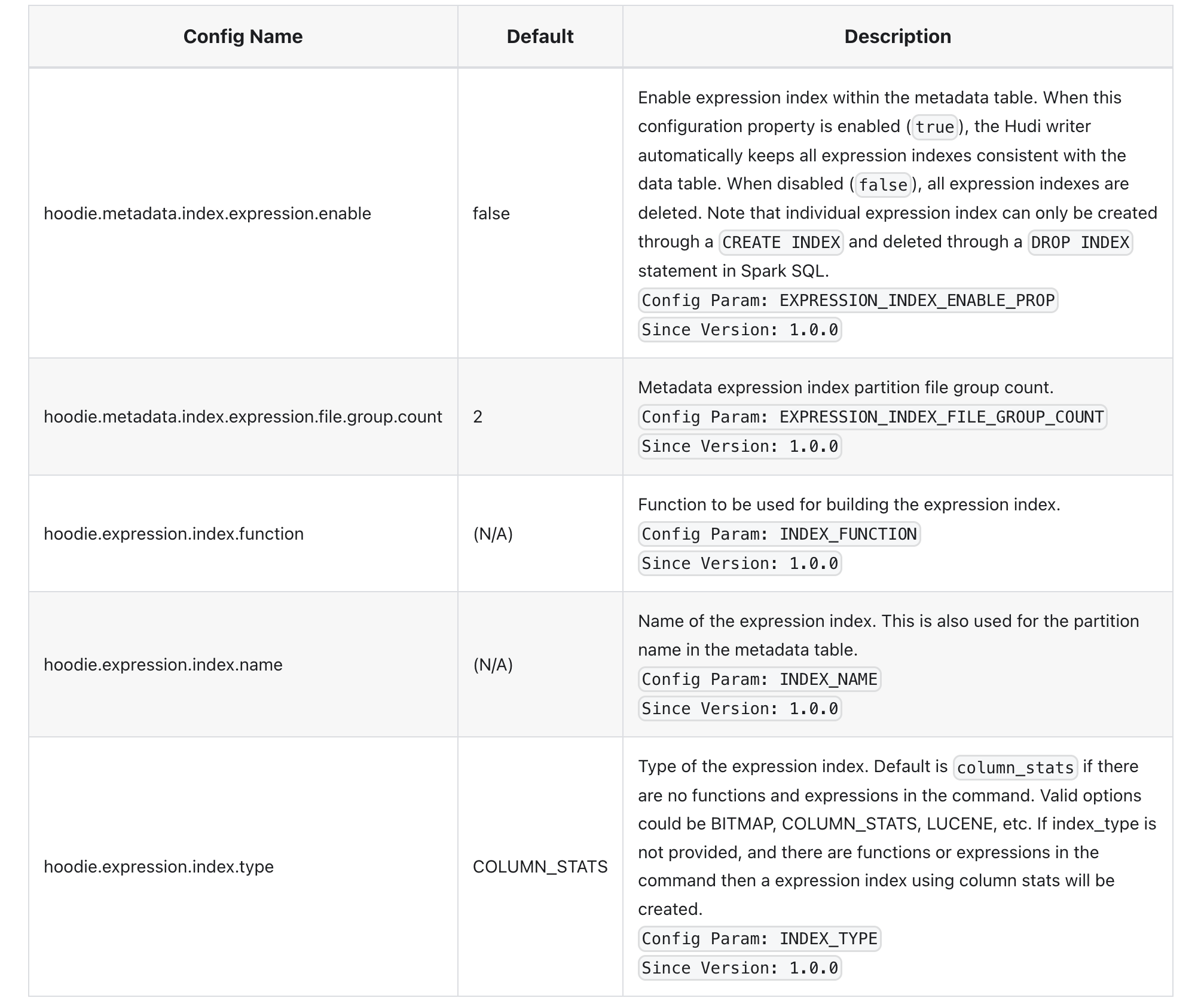
Hudi系列:Hudi核心概念之索引(Indexs)
京东科技开发者
·
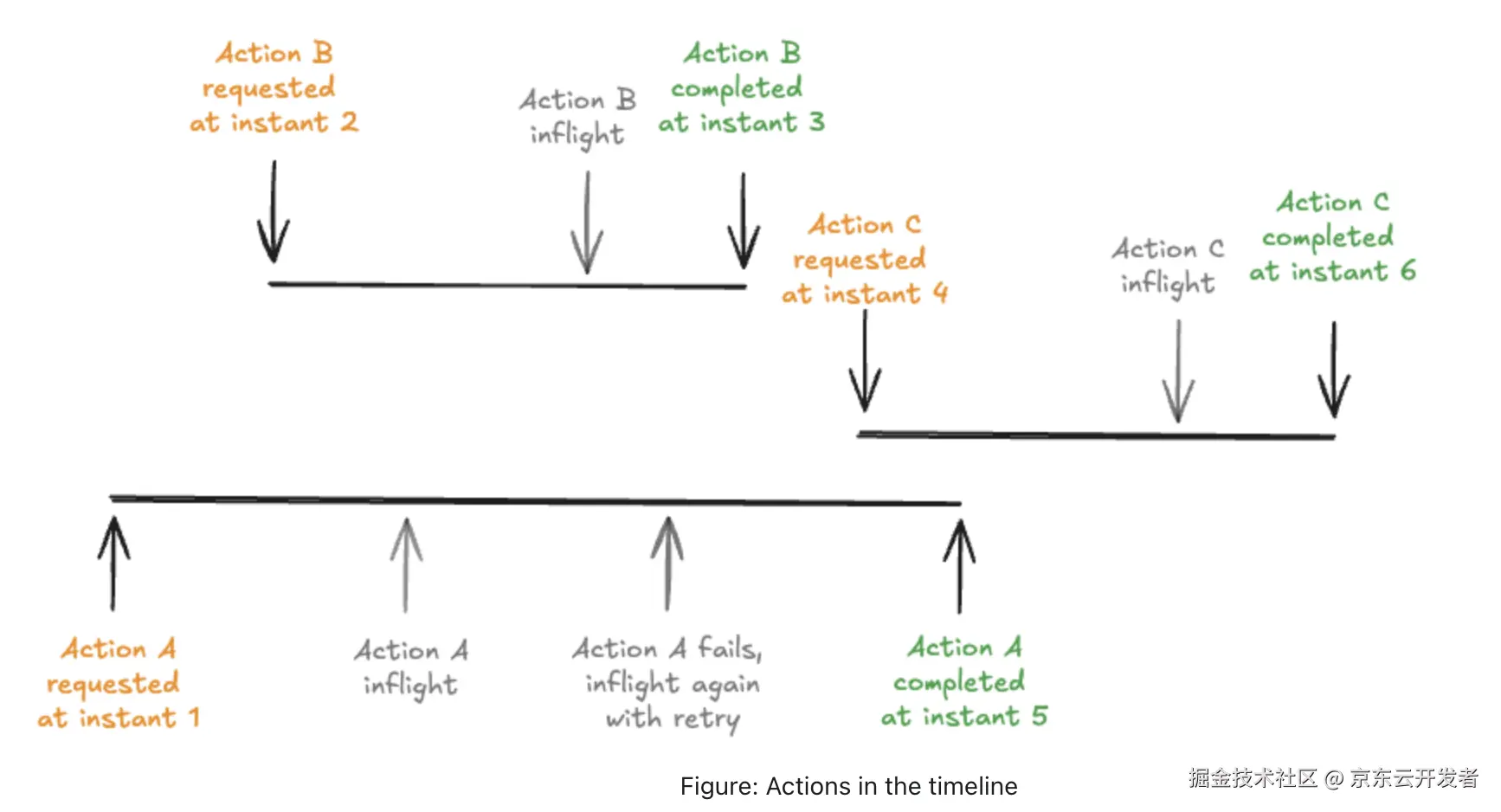
Hudi系列:Hudi核心概念之时间轴(TimeLine)
京东科技开发者
·
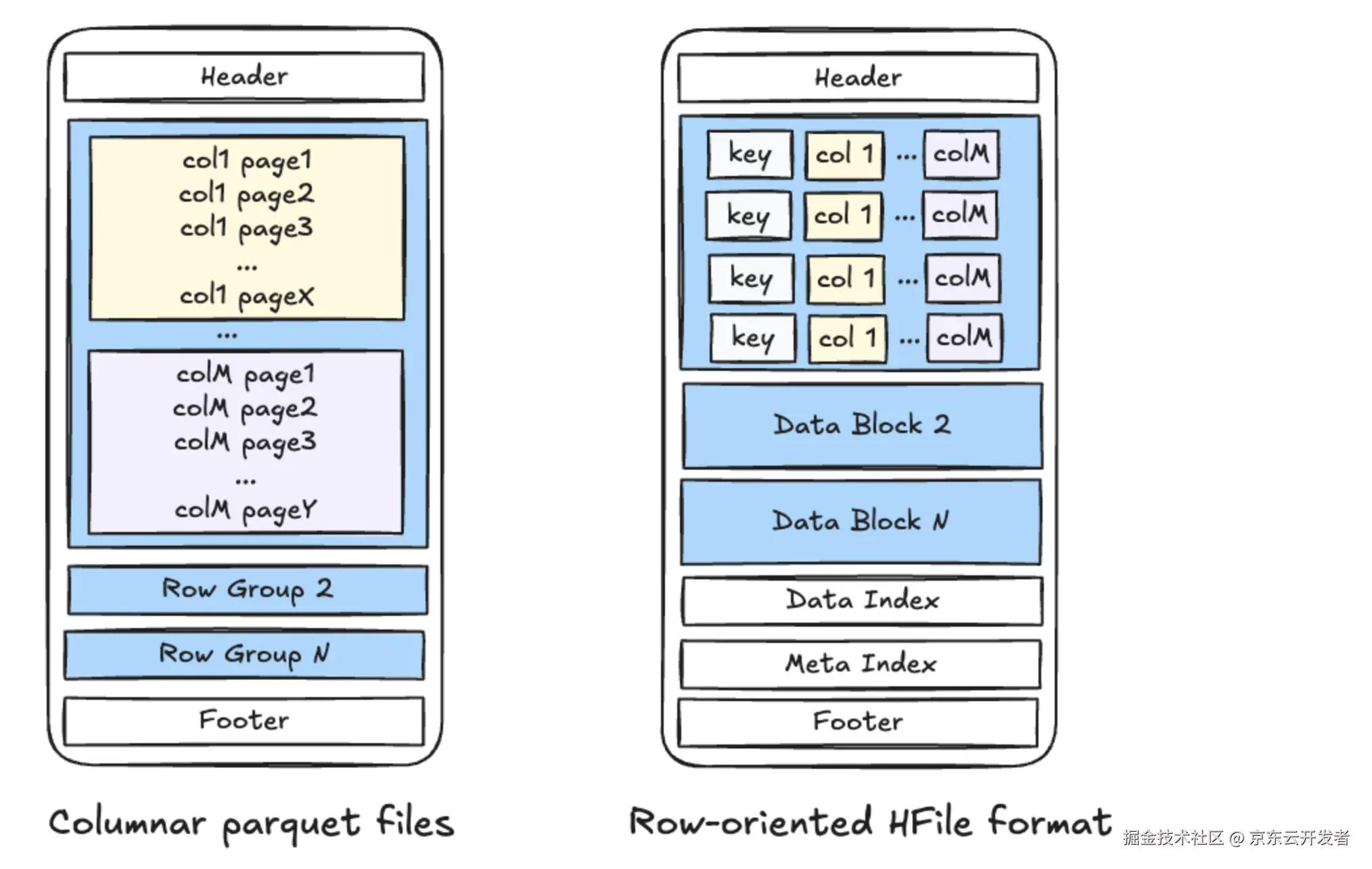
Hudi系列:Hudi核心概念之文件布局(Storage Layouts)
京东科技开发者
·

EMR Flink-Hudi 实时分析系统成本优化
亚马逊AWS官方博客
·


【Hadoop】Hudi 基础知识详解
小令童鞋
·
使用 Flink Hudi 处理变更数据流并通过 Redshift Spectrum 进行数据分析实践
亚马逊AWS官方博客
·
使用 Apache Flink 在 Amazon EMR 上构建统一数据湖
亚马逊AWS官方博客
·
