
Hudi系列:Hudi核心概念之索引(Indexs)
内容提要
Hudi是一个数据湖框架,支持多种索引机制以提高数据处理效率。其核心概念包括时间轴、文件布局和表类型,提供COW和MOR两种表类型,支持快速插入和查询。通过多态索引、布隆过滤器和记录索引等机制,优化数据的读取和写入性能,并允许创建二级索引以加速非主键列的查询。
关键要点
-
Hudi是一个数据湖框架,支持多种索引机制以提高数据处理效率。
-
Hudi的核心概念包括时间轴、文件布局和表类型,提供COW和MOR两种表类型。
-
COW表支持快速插入和删除操作,而MOR表允许限制需要合并的更改记录数量。
-
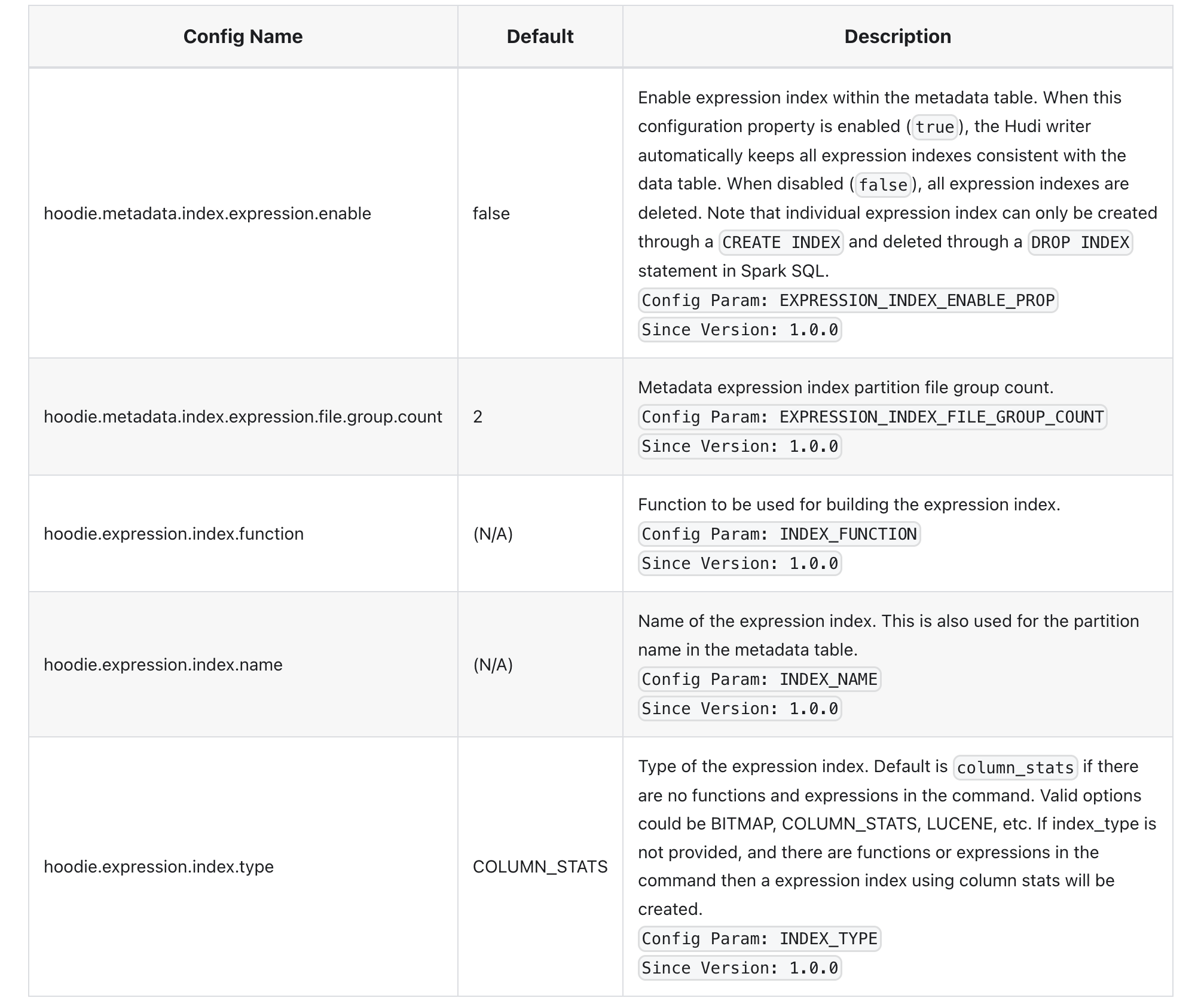
Hudi支持多态索引,包括布隆过滤器、记录索引、表达式索引和二级索引,以优化数据的读取和写入性能。
-
全局索引要求在全表范围内键唯一,而非全局索引仅在某个分区内要求键唯一。
延伸解读
Hudi的索引机制优势
Hudi通过多种索引机制显著提升数据处理效率,尤其在快速插入和查询方面。与传统的Hive相比,Hudi的索引可以避免全表扫描,从而减少了数据合并的开销。这使得Hudi在处理大规模数据时表现出色,尤其适合需要高效数据更新和查询的场景。
COW与MOR表的选择
Hudi提供COW和MOR两种表类型,各有优缺点。COW表适合频繁的插入和删除操作,而MOR表则在读取时合并数据,适合对实时性要求较高的应用。用户在选择时应根据具体的业务需求和数据特性进行权衡,以优化性能和资源使用。
多态索引的灵活性
Hudi的多态索引支持多种索引类型,如布隆过滤器和记录索引,能够根据不同的查询需求进行优化。这种灵活性使得用户可以根据数据访问模式选择合适的索引,从而提高查询效率,尤其是在处理复杂查询时,能够显著减少响应时间。
延伸问答
Hudi的核心概念有哪些?
Hudi的核心概念包括时间轴、文件布局和表类型,提供COW和MOR两种表类型。
COW和MOR表有什么区别?
COW表支持快速插入和删除操作,而MOR表允许限制需要合并的更改记录数量。
Hudi支持哪些类型的索引?
Hudi支持多态索引,包括布隆过滤器、记录索引、表达式索引和二级索引。
全局索引和非全局索引有什么不同?
全局索引要求在全表范围内键唯一,而非全局索引仅在某个分区内要求键唯一。
Hudi如何优化数据的读取和写入性能?
Hudi通过多态索引、布隆过滤器和记录索引等机制来优化数据的读取和写入性能。
什么是布隆过滤器在Hudi中的作用?
布隆过滤器用于标记传入的记录,通过基于范围的修剪来优化记录键的查找。
