LoRA(低秩适应)是一种高效的微调方法,通过低秩分解减少大模型微调时的参数量和存储需求,仅更新少量参数,接近全参数微调效果。QLoRA 通过量化技术进一步提升了在单卡上微调大模型的能力。LoRA 在指令微调和风格迁移等任务中表现优异,但在需要大量新知识的场景中可能不如全参数微调。
Sakana AI 提出了两种方法:Text-to-LoRA (T2L) 和 Doc-to-LoRA (D2L),通过轻量级超网络实现大型语言模型的高效定制,显著降低内存和延迟,并支持零样本任务适应和跨模态知识迁移。
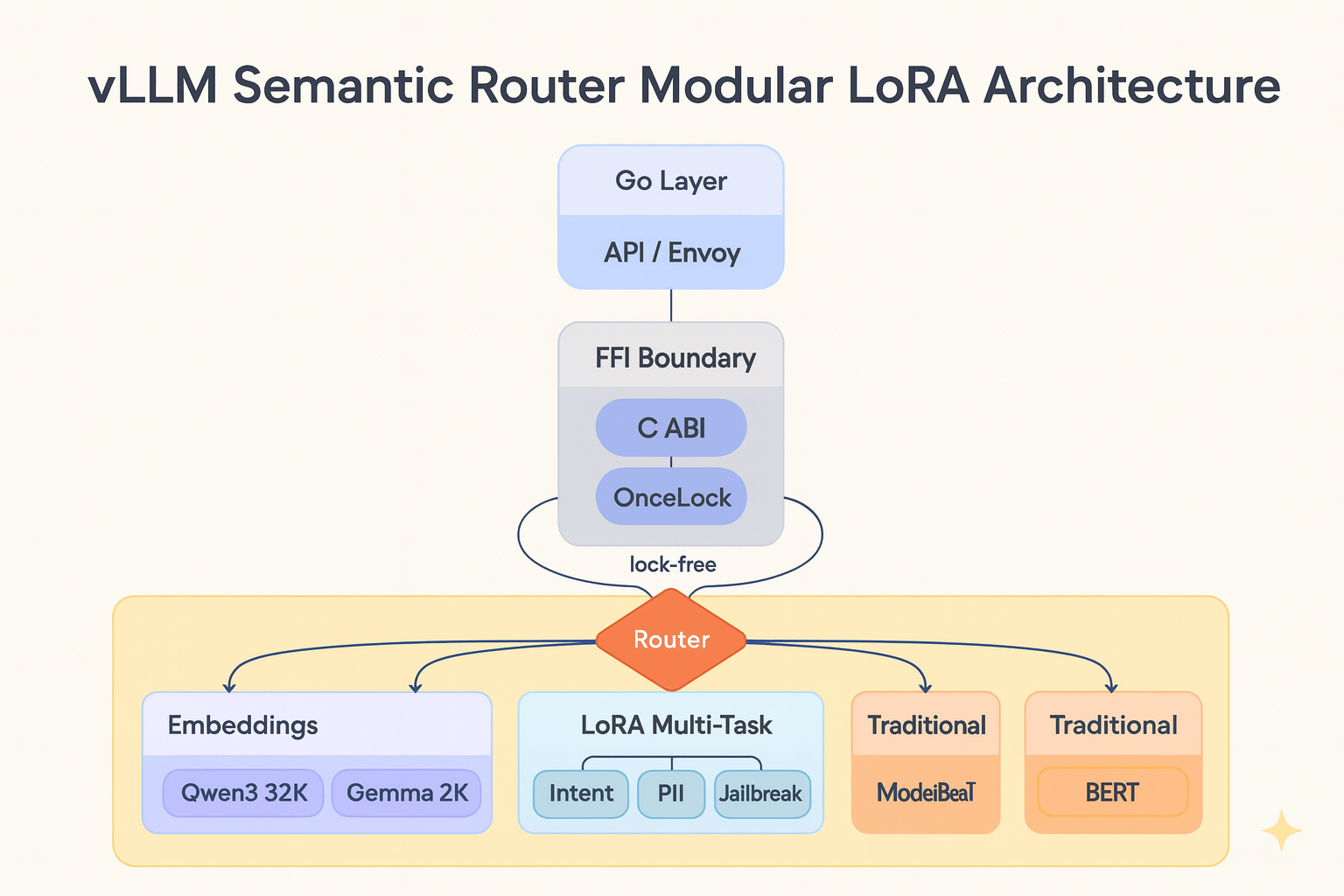
语义路由系统面临扩展挑战,多个模型独立运行导致计算成本线性增长。通过重构vLLM语义路由器的分类层,采用模块化架构、低秩适应(LoRA)和并发优化,解决了这一问题。新架构支持多模型,提升了多语言处理能力和长文档支持,显著提高了分类效率和并发性能。
本实验搭建了一个基于云主机和Whisper语音识别系统的平台,结合云计算与深度学习技术,帮助开发者优化模型训练和进行语音识别处理,掌握数据预处理和模型训练等关键步骤。适合企业、开发者和学生,预计时长120分钟。
vLLM 是一款加速大语言模型推理的框架,解决了内存管理瓶颈,实现了 KV 缓存内存的零浪费。它支持多种量化技术和 LoRA 适配器,并提供离线推理的示例和使用指南。
机器之心数据服务现已上线,提供高效稳定的数据获取,简化数据爬取流程。
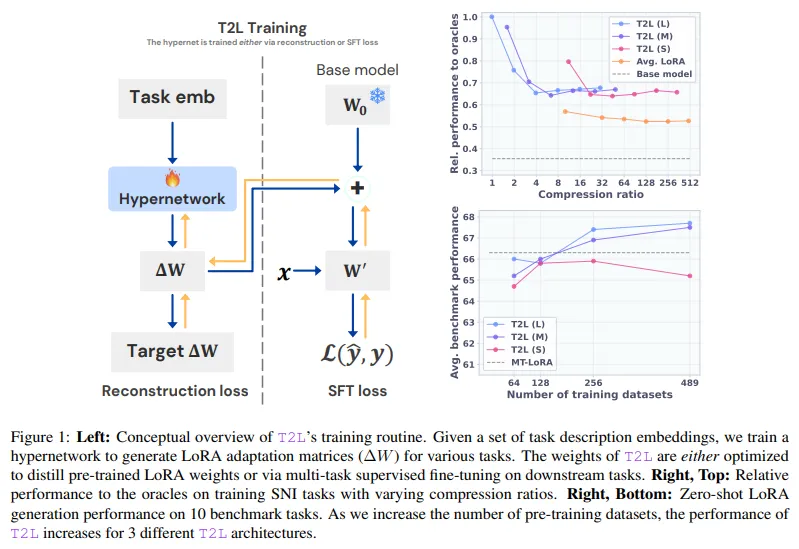
Transformer模型在自然语言处理领域取得了显著进展,但在新任务上仍需复杂的微调。研究者提出了Text-to-LoRA (T2L)技术,能够根据任务描述即时生成LoRA适配器,从而减少训练时间和成本。T2L在多个基准测试中表现优异,展现了其在模型适配方面的灵活性和高效性。
SakanaAI推出的Text-to-LoRA(T2L)技术简化了大模型的微调流程,用户只需一句话即可生成LoRA,压缩率达到80%,准确率仅下降1.2%。该技术使非技术用户能够轻松适配模型,推动“文本驱动”时代的到来。
本文介绍了如何通过微调已有文档,优化金仓平台的智能体,以提升其在离线环境下回答数据库迁移问题的能力。采用LoRa技术和Spring AI框架处理文档数据,实现模型私有化部署,从而提高响应速度和数据安全性。
机器之心数据服务现已上线,提供高效稳定的数据获取服务,简化数据爬取流程。
本研究提出TT-LoRA MoE框架,结合参数高效微调与稀疏专家混合路由,解决大型模型部署的可扩展性问题,显著提升多任务推理的计算效率与灵活性。
本研究提出了Tina微型推理模型系列,采用低秩适应(LoRA)技术,在仅有1.5亿参数的基础上实现高效推理。Tina在计算成本低的情况下,其推理性能与现有模型竞争,甚至超越。
本研究提出了一种经济有效的方法,将大型语言模型(LLMs)应用于留学背景的学术咨询,特别适用于低资源环境中的文化适应。通过低秩适应和4位量化,模型在领域特异性和计算效率上显著提升,最终实现92%的推荐准确率。
该研究解决了在基于LoRA的持续学习中,关键参数在后任务学习后依然显著变化的问题。提出通过冻结视觉变换器中最关键的参数矩阵,并在正交LoRA调优的基础上,提出了正交LoRA组合(LoRAC),以进一步增强方法的灵活性。实验结果表明,该方法在多个持续学习基准测试中达到了SOTA性能,显著改善了准确性和遗忘率。
该研究解决了在多轮设置中切换LoRA时高效性不足的问题,通过引入激活的LoRA方法,仅在调用后适应序列中的权重,从而避免了重计算整个缓存。这一创新使得基模型的KV缓存可以被快速利用,创造出所谓的“内在特性”模型,实现了专门化操作的高效执行。
自2023年9月推出以来,Workers AI团队致力于提升平台质量,推出了快速推理的投机解码、异步批处理API和扩展的LoRA支持,显著提升了推理速度和用户体验。
本研究提出了一种名为AC-LoRA的新方法,解决个性化图像生成中LoRA参数调整的问题。该方法通过奇异值分解和动态启发式算法,实现了快速高效的个性化艺术风格图像生成,模型适应性显著提高,验证结果显示多个指标平均提升9%。
腾讯天琴实验室全面开源lyraDiff,提升文生图模型推理速度最高6.1倍,支持多种图像生成模型,并实现无损切换插件,优化推理效率,降低生成成本,适合开发者使用。
本研究提出了条件递归扩散框架ORAL,旨在解决大语言模型中低秩适应方法的可扩展性和可控性问题。实验结果表明,ORAL生成的LoRA参数在多项任务中表现优异。
本研究探讨了低秩适应(LoRA)在微调预训练模型时的学习动态,提出了基于梯度流的分析方法。通过谱初始化,改善了原模型与目标矩阵的错位,理论证明小规模谱初始化能以任意精度收敛,实验结果验证了该方法的有效性。
完成下面两步后,将自动完成登录并继续当前操作。