
从单体到模块化:通过可扩展的LoRA扩展语义路由
内容提要
语义路由系统面临扩展挑战,多个模型独立运行导致计算成本线性增长。通过重构vLLM语义路由器的分类层,采用模块化架构、低秩适应(LoRA)和并发优化,解决了这一问题。新架构支持多模型,提升了多语言处理能力和长文档支持,显著提高了分类效率和并发性能。
关键要点
-
语义路由系统面临扩展挑战,多个模型独立运行导致计算成本线性增长。
-
通过重构vLLM语义路由器的分类层,采用模块化架构、低秩适应(LoRA)和并发优化,解决了这一问题。
-
新架构支持多模型,提升了多语言处理能力和长文档支持,显著提高了分类效率和并发性能。
-
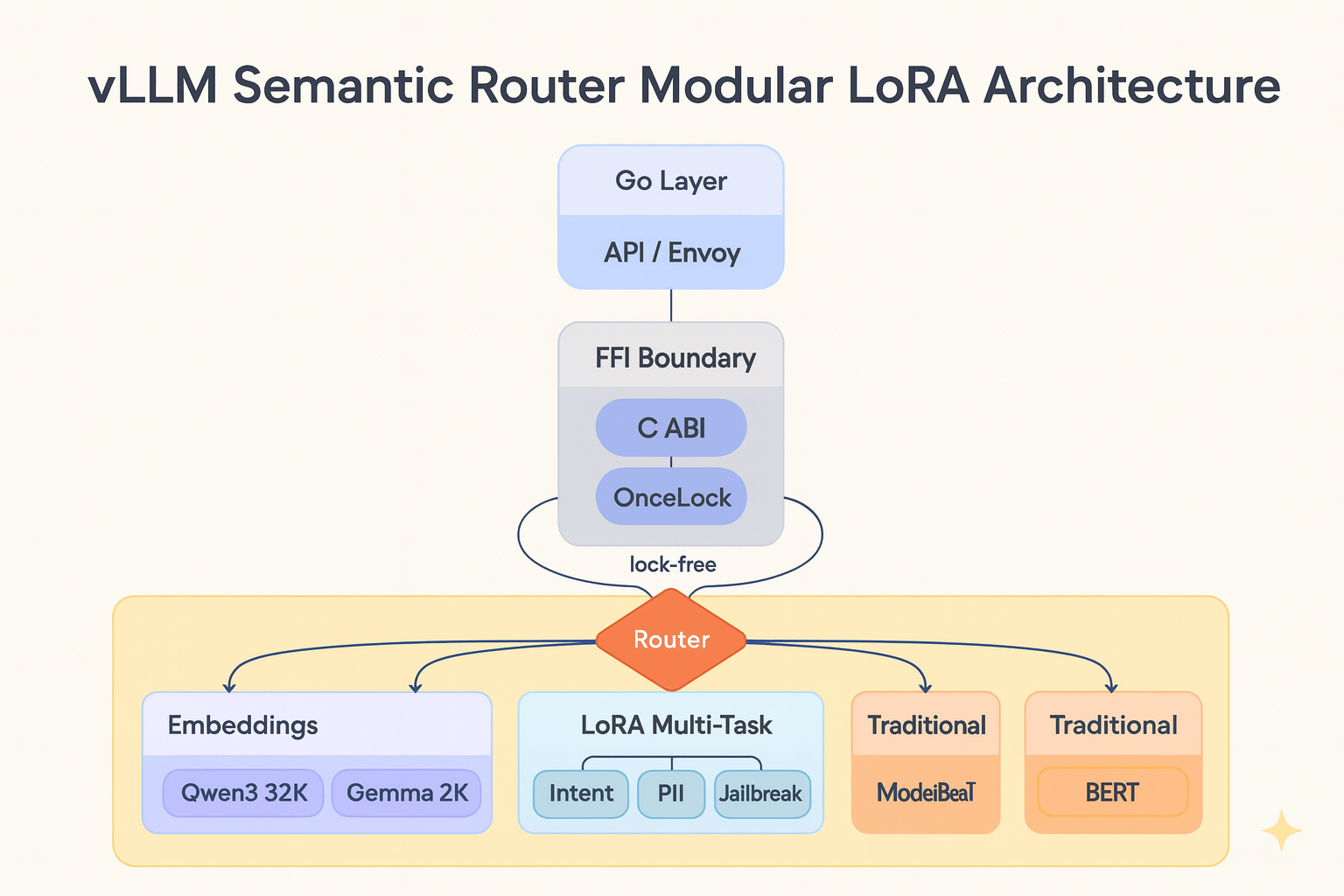
之前的实现主要依赖BERT和ModernBERT,存在语言覆盖、上下文长度和模型耦合等限制。
-
重构引入了分层架构,核心功能独立于特定模型,新模型架构可无缝集成。
-
Qwen3-Embedding支持长达32,768个token的上下文,适合多语言路由场景。
-
EmbeddingGemma-300M专注于小模型尺寸,同时保持质量,支持2,048个token的上下文。
-
LoRA通过共享基础模型计算,显著提高了多任务分类的效率。
-
OnceLock替代lazy_static,消除了锁争用,提高了并发性能。
-
Flash Attention 2支持GPU加速,显著提高了注意力计算的速度和效率。
-
Rust作为核心分类引擎提供高性能和内存安全,Go FFI绑定解决云原生环境中的部署挑战。
-
双语言架构提供灵活的部署选项,支持嵌入模式和进程隔离。
-
模块化架构为未来扩展提供基础,支持添加新嵌入模型和自定义LoRA适配器。
延伸解读
模块化架构的优势
新架构通过模块化设计,允许不同模型的无缝集成。这种灵活性不仅提高了系统的扩展性,还能根据任务需求选择最合适的模型,从而优化性能。这对于多语言处理和长文档支持尤为重要,能够有效应对传统模型的局限性。
低秩适应(LoRA)的效率提升
LoRA通过共享基础模型的计算,显著降低了多任务分类的复杂度。相比于传统方法,LoRA在处理多个分类任务时,能够减少计算开销,提高响应速度。这一特性在高并发场景下尤为重要,能够有效提升系统的整体性能。
并发性能的优化
新架构采用OnceLock替代了传统的lazy_static,消除了锁争用问题。这一改进使得在高并发请求下,系统能够实现更高的吞吐量,确保多个请求可以并行处理,提升了整体的响应效率。
GPU加速的潜力
Flash Attention 2的集成为模型提供了显著的计算加速,尤其是在处理长序列时。对于支持该技术的GPU,注意力计算速度可提高3-4倍,这在高吞吐量的应用场景中具有重要意义,能够有效提升系统的处理能力。
延伸问答
什么是LoRA,它如何提高分类效率?
LoRA(低秩适应)通过共享基础模型计算,减少了每个分类任务的计算复杂度,从而显著提高了多任务分类的效率。
新架构如何解决语义路由系统的扩展挑战?
新架构通过模块化设计和并发优化,允许多个模型并行运行,降低了计算成本并提高了分类效率。
Qwen3-Embedding与ModernBERT相比有什么优势?
Qwen3-Embedding支持长达32,768个token的上下文,适合处理长文档,并且在多语言支持上表现更佳。
OnceLock在新系统中有什么作用?
OnceLock替代了lazy_static,消除了锁争用,提高了并发性能,允许多个请求并行处理。
Flash Attention 2如何提高注意力计算的效率?
Flash Attention 2通过在快速的片上SRAM内存中处理计算,避免了重复读取慢速GPU DRAM,从而显著提高了计算速度和效率。
Rust在语义路由系统中的优势是什么?
Rust提供高性能、内存安全和无垃圾回收的特性,适合低延迟推理,确保了并发处理的安全性。
