本文介绍了语言模型微调的原因、数据集、过程及技术。微调能提升模型在特定领域的理解,适用于指令跟随和对话生成,且通常比预训练更快。文中还提到了一些高级微调技术,如基于人类反馈的强化学习(RLHF)和低秩适应(LoRA)。
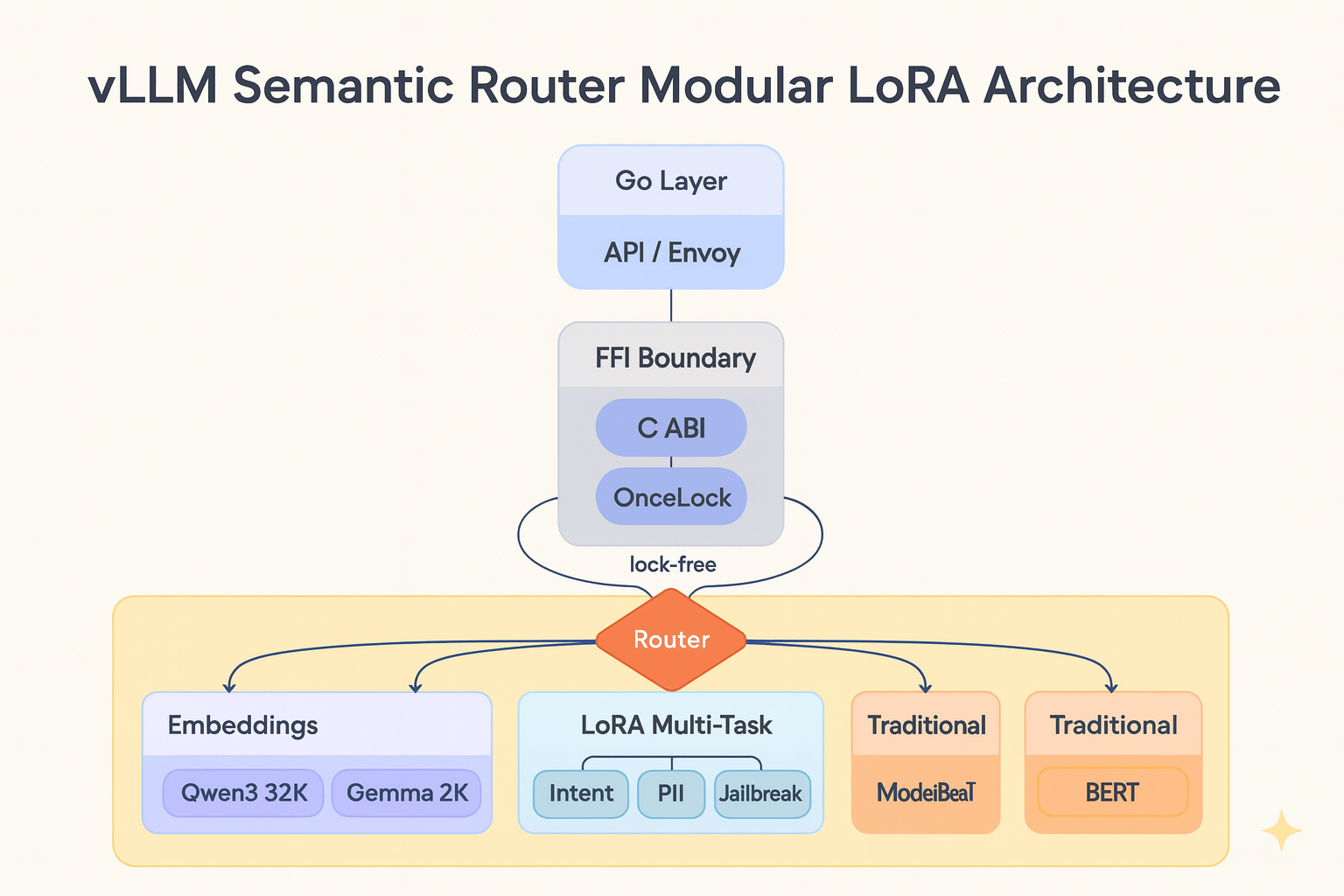
语义路由系统面临扩展挑战,多个模型独立运行导致计算成本线性增长。通过重构vLLM语义路由器的分类层,采用模块化架构、低秩适应(LoRA)和并发优化,解决了这一问题。新架构支持多模型,提升了多语言处理能力和长文档支持,显著提高了分类效率和并发性能。
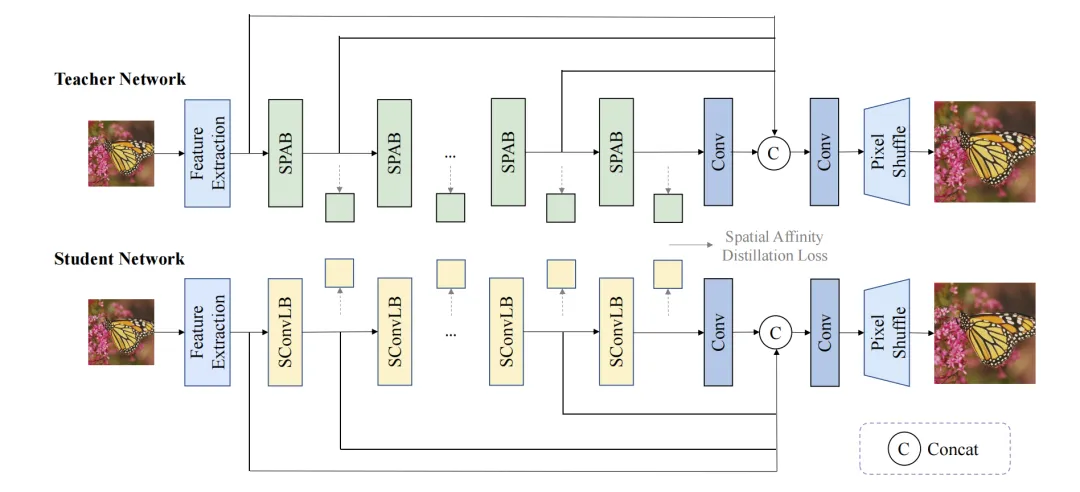
本文介绍了上海交通大学与传音团队合作的DSCLoRA模型,该模型在CVPR NTIRE 2025高效超分辨率挑战赛中获第一名。DSCLoRA结合低秩适应和知识蒸馏技术,显著提升超分辨率性能,且未增加计算成本。通过引入ConvLoRA,DSCLoRA在多个基准数据集上表现优异,展示了模型复杂度与性能的良好平衡。
本研究提出了LoRa-FL框架,旨在边缘设备上训练低秩一-shot图像检测模型。该框架通过低秩适应技术降低计算和通信成本,同时保持准确性。实验结果表明,其在多个数据集上具有竞争力的检测性能,适合资源受限环境。
本研究提出了Tina微型推理模型系列,采用低秩适应(LoRA)技术,在仅有1.5亿参数的基础上实现高效推理。Tina在计算成本低的情况下,其推理性能与现有模型竞争,甚至超越。
本研究提出了一种经济有效的方法,将大型语言模型(LLMs)应用于留学背景的学术咨询,特别适用于低资源环境中的文化适应。通过低秩适应和4位量化,模型在领域特异性和计算效率上显著提升,最终实现92%的推荐准确率。
Chinese-Vicuna是一款基于LLaMA架构的中文指令跟随模型,采用低秩适应技术进行微调,旨在低资源环境中实现经济高效的部署。该模型在翻译、代码生成和领域特定问答等任务中表现优异,为中文大语言模型应用提供了多功能基础。
本文提出了一种新方法LoRI,旨在减少多任务低秩适应中的参数干扰和开销。通过随机投影和任务特定掩模,LoRI显著降低了可训练参数数量,同时保持强大性能,实验表明其可减少95%的可训练参数。
本研究探讨了低秩适应(LoRA)在航拍图像跨域少样本目标检测中的应用。将LoRA集成到DiffusionDet中,结果显示在1-shot和5-shot的低样本设置下,性能略有提升,表明其在资源有限情况下的适应潜力,对少样本学习的微调策略研究具有重要意义。
本研究提出了条件递归扩散框架ORAL,旨在解决大语言模型中低秩适应方法的可扩展性和可控性问题。实验结果表明,ORAL生成的LoRA参数在多项任务中表现优异。
本研究提出了一种基于量子加权张量混合网络的高效微调方法,克服了经典低秩适应在复杂任务中的局限性。该方法在大型模型微调中减少了76%的参数,训练损失比传统LoRA降低了15%。
本研究提出了一种创新的低秩适应方法,用于优化大型语言模型中的负偏好,成功去除敏感内容,且在学习稳定性上表现优异。
本研究探讨了低秩适应(LoRA)在微调预训练模型时的学习动态,提出了基于梯度流的分析方法。通过谱初始化,改善了原模型与目标矩阵的错位,理论证明小规模谱初始化能以任意精度收敛,实验结果验证了该方法的有效性。
本研究提出了一个农作物疾病诊断的多模态数据集(CDDM),包含137,000张图像和100万个问答对,结合视觉与文本数据,提升农业专家的诊断能力。通过低秩适应微调策略,显著提高了多模态模型在疾病诊断中的表现。
本文介绍了SELMA,一个用于虚拟助手交互的语音启用语言模型。SELMA同时处理三项主要任务和两项辅助任务,采用低秩适应模块进行高效训练。实验结果表明,SELMA在语音触发检测和设备导向语音检测任务上显著提高了性能,简化了虚拟助手的输入处理流程。
要在自己的数据上训练专用的LLM,最简单的方法是使用低秩适应(LoRA)。LoRA通过低秩分解更新模型权重,保持预训练层不变,并在每层注入可训练的矩阵。QLoRA利用量化技术减少内存使用,QA-LoRA进一步降低计算负担,LongLoRA通过稀疏局部注意力适应更长上下文,S-LoRA支持在单个GPU上部署多个LoRA模块。
本研究提出的VesselSAM模型结合了Atrous Attention和低秩适应技术(LoRA),显著提高了主动脉血管分割的精度,整体DSC分数达到93.50%。该模型在多个医疗中心的测试中表现优异,为临床应用提供了新的方案。
本研究通过电路分析深入探讨大型语言模型(LLMs)的微调机制,提出了一种基于电路的低秩适应方法(LoRA),实验结果显示性能提升了2.46%。
本研究提出了一种低秩个性化文本转语音生成模型(LoRP-TTS),旨在改善传统语音合成模型在嘈杂环境中模拟非工作室质量样本的不足。该模型通过低秩适应方法显著提高了说话者的相似度,同时保持了内容的自然性,为多样化语音语料库的建立提供了基础。
本文探讨了视觉语言模型在使用预训练图像编码器时的图像理解错误问题,提出了新方法LoRSU(带结构更新的低秩适应),有效选择性更新图像编码器。研究表明,LoRSU在资源受限环境中显著提升计算效率,开销减少超过25倍,同时保持性能,成为图像编码器适应的重要解决方案。
完成下面两步后,将自动完成登录并继续当前操作。