DAC(自主访问控制)和MAC(强制访问控制)是Linux的安全机制。DAC基于用户ID(UID)和组ID(GID),而MAC在此基础上增加了强制策略。LSM框架支持多个安全模块的堆叠,SELinux采用类型强制,AppArmor则使用路径强制。SELinux复杂但粒度细,AppArmor简单但粒度粗。BPF_LSM提供可编程的安全策略。
FlowDB 是一个基于 Rust 的嵌入式 LSM 引擎和 JSON 文档数据库,提供 LSM-Tree 和 JsonDB API,支持多索引、事务和范围扫描,性能优于 RocksDB,点查询速度快 11 倍,适合高效存储和检索 JSON 数据。
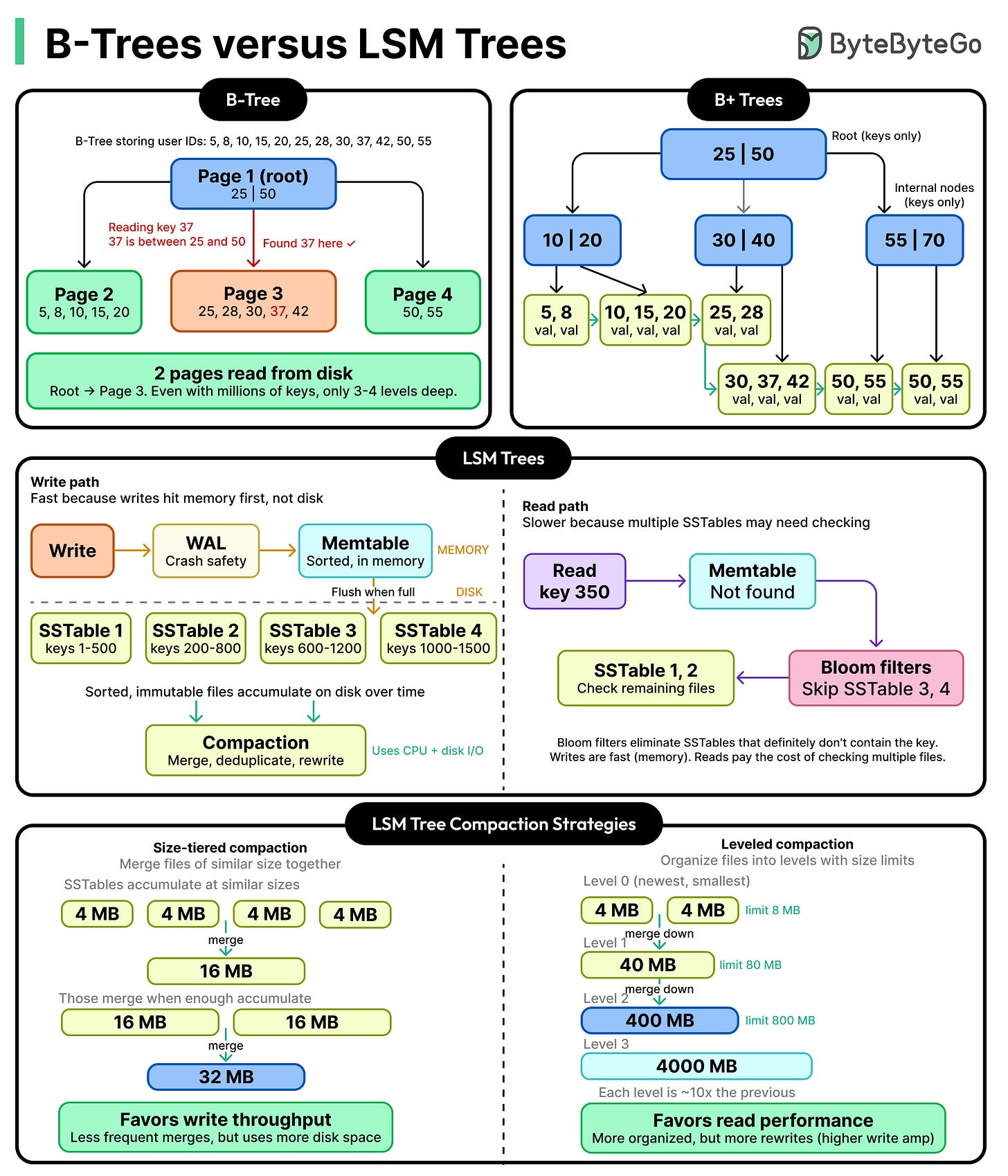
B树和LSM树是数据库中的两种主要数据组织方式。B树在磁盘上保持数据排序,读取速度快但写入成本高;LSM树在内存中缓冲写入,批量刷新到磁盘,写入便宜但读取成本高。理解它们的优缺点对系统设计至关重要。
B+树和LSM树是两种主要的数据结构,分别代表原地更新和追加写入的存储方式。B+树优化读取和空间,但写放大较高;LSM树优化写入,但读取和空间放大较高。RUM猜想表明,无法在读、写和空间放大上同时达到最优。B+树适合OLTP场景,而LSM树在写入密集型应用中表现更好。选择存储引擎时需考虑具体应用需求。
本文介绍了一个完整的LSM-Tree数据库引擎的实现,分为两个部分:第一部分使用C语言组装各个组件,提供六个API;第二部分用Rust重写核心模块,记录编译过程中的真实故事并进行性能对比。文章详细描述了数据库的内部结构、读写路径、崩溃恢复机制及后台线程的工作原理,强调了Rust在安全性方面的优势,并通过基准测试比较了C、Rust和LevelDB的性能,指出各自的优缺点。
本文讨论了LSM-Tree中的Compaction机制,解决了SSTable只增不删的问题。Compaction通过合并多个SSTable文件,回收无效数据,提升读性能。文章介绍了不同层级的设计、Compaction的触发条件、文件选择策略及去重逻辑,确保数据的有序性和一致性,并管理版本信息以支持并发读写操作。
本文介绍了SSTable的构建与读取过程,重点在于数据块的前缀压缩和布隆过滤器的实现,强调其在减少无效I/O中的作用。SSTable通过分块存储数据,利用索引和布隆过滤器提高查找效率,避免不必要的磁盘读取。文章还提供了相关的C代码实现。
本文介绍了WAL(Write-Ahead Log)和MemTable的实现,解决了数据持久性问题。WAL通过先写日志再写内存,确保崩溃后数据可恢复。MemTable使用跳表结构,支持高效的插入和查找。文章讨论了WAL的记录格式、分片策略及崩溃恢复的正确性,确保数据在系统崩溃时不会丢失。
LSM-Tree(日志结构合并树)是一种适合写入远多于读取的存储系统的结构。其核心思想是将数据先写入内存中的有序结构,再顺序写入磁盘,以避免随机写入的性能瓶颈。与B-Tree相比,LSM-Tree通过追加写和后台归并优化写入性能,适合时序数据库和日志存储。文章介绍了LSM-Tree的组件及其工作原理,包括WAL、MemTable、SSTable和Compaction等。
该系列文章通过五篇深入探讨如何从零构建LSM-Tree KV存储引擎,涵盖设计决策、组件功能及Rust重写,涉及WAL、MemTable、SSTable、Compaction等关键概念,最终提供完整引擎及性能对比。
数据库是软件系统的重要组成部分,能够高效存储和检索大量数据。随着数据量的增加,LSM树(日志结构合并树)成为一种高效的存储系统。本文介绍了LSM树的关键组件,如MemTable、SSTable和WAL,强调了写入速度和数据持久性的重要性,并探讨了删除和合并数据的挑战。
本文介绍了如何用Java从零构建LSM树存储引擎,重点在数据管道的实现。JavaLSM提供简单的键值接口,支持内存缓冲和磁盘SSTables,具备快速读取、自动压缩和崩溃恢复等功能。通过红黑树和布隆过滤器的使用,优化了存储和查询效率,增强了对LSM存储引擎的理解。
本文介绍了日志结构合并树(LSM-Tree)的基本概念及其在高吞吐量写操作中的应用。LSM-Tree通过内存中的Memtable和磁盘上的SSTable优化数据写入,并使用WAL确保数据安全。删除操作采用“墓碑”机制,查询时利用Bloom过滤器提高效率。最后,文章展示了如何从零构建基于LSM-Tree的存储引擎。
Linux安全主要依赖自主访问控制(DAC),但对恶意软件的保护有限。强制访问控制(MAC)通过安全规则检查程序操作。SeLinux和AppArmor是两种MAC实现,前者复杂且依赖支持的文件系统,后者使用白名单进行权限管理,允许基于应用的限制。Ubuntu和SUSE默认使用AppArmor,而RHEL则使用SeLinux。
该研究提出了多种新型YOLO架构(如RCS-YOLO、BGFG-YOLO、YOLO-OB),在脑肿瘤和息肉检测中实现了高准确性和实时性能。通过多尺度特征提取和注意力机制,显著提升了医学影像分析中的目标检测效果。
本文探讨了大型语言模型(LLMs)与知识图谱结合的研究进展,提出了多种增强模型知识整合能力的方法。研究表明,通过结构化知识注入和知识图谱检索,LLMs在推理和任务执行上显著提升,尤其在复杂问题解决方面表现优异。
SnapKV 是一种创新方法,通过选择重要的键值位置,减少大型语言模型的内存和计算开销,同时保持性能。该方法结合自适应 KV 缓存和混合精度 KV 缓存,显著提高了压缩比和效率。QAQ 和 LESS 进一步优化了 KV 缓存,降低了部署难度。KCache 和 Scissorhands 技术提高了推理过程的吞吐量,KV-Runahead 则加速了模型的前置阶段。
本文探讨了在ARM64架构上使用ftrace的BPF LSM的差异,并介绍了作者在MacBook M2上开发eBPF程序时遇到的问题。作者通过使用bpftrace和trace-cmd工具来调查问题,并发现在Linux 5.15和6.1内核上加载BPF LSM程序时出现了错误。经过分析,作者发现这是因为缺少对aarch64架构的支持。然而,作者指出这个问题将在下一个6.4版本的Linux内核中得到修复。
IBM Watson团队和IBM研究团队开发了一种新的大型语音模型(LSM),用于电话助手和实时通话转录等客户服务场景。与OpenAI的Whisper模型相比,IBM的LSM在短文本英语用例中的词错误率(WER)降低了42%,模型大小也小了5倍,处理速度快了10倍。LSM在长文本用例中也表现出色。现在,英语和日语的新LSM已在Watson Speech to Text和Watson Assistant电话客户中的封闭测试中提供。
本文介绍了几种数据结构的发展和特点。完全二叉树和平衡二叉树是基础,二叉搜索树(BST)查询高效但可能退化为链表。AVL树是平衡二叉搜索树,通过旋转保持平衡,但旋转成本高。红黑树牺牲部分平衡性以减少旋转。B树适合大数据量,减少磁盘IO,B+树优化了磁盘IO次数和范围查询。LSM树适合写多读少的场景,牺牲读性能以提升写性能。
完成下面两步后,将自动完成登录并继续当前操作。