Kyverno is a Kubernetes-native policy engine that validates, mutates, and generates resources before workloads reach your cluster, enforcing security and compliance rules as code, without...
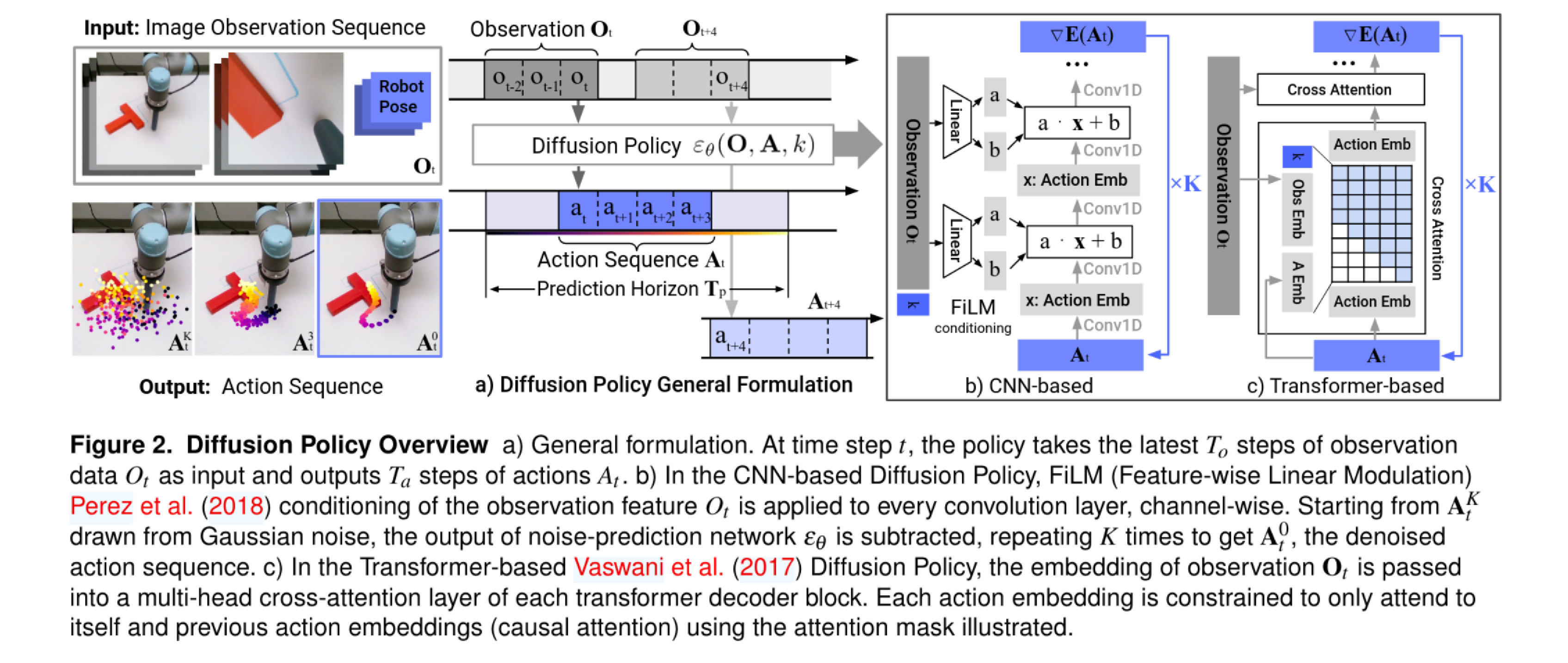
本文讨论了Diffusion Policy在机器人动作规划中的应用。通过神经网络预测噪声并逐步去噪,机器人能够生成精准的动作轨迹。尽管面临视觉遮挡和物理干扰,机器人依然能重新规划路径,展现出强大的适应能力。研究表明,该模型在学习物理系统动力学方面表现出色。
GigaWorld-Policy是一种高效的以动作为中心的世界-动作模型,旨在提升机器人策略学习。该模型结合未来视觉动态与动作预测,优化学习效率并减少推理延迟。通过课程式训练和多样化视频源注入物理先验,在机器人数据上进行预训练,以增强对交互动力学的鲁棒性。
The Most Important Foreign Policy Speech in Years
CHIP是一种自适应柔顺控制方法,通过事后干扰提升人形机器人在外力作用下的稳定性和灵活性。该方法简化了运动编辑问题,改善了机器人在擦拭、开门和多机器人协作等任务中的表现,并可无缝集成到现有系统中,具有广泛应用潜力。
IAM Policy Autopilot是一款开源工具,能够分析应用代码并自动生成AWS IAM策略,帮助开发者加速开发流程。它支持Python、TypeScript和Go,并与多种AI编程助手集成,提供专业的IAM知识。
开源是用户和社区的集合,依赖法律管理源代码,具有经济价值。其起源、自由软件主张及法律保障值得探讨。开源促进创新,经历了从个人合作到商业模式的发展,已成为社会的一部分。
本文介绍了一种结合强化学习与视觉-语言-动作模型的微调方法ConRFT,旨在提升机器人任务的样本效率和安全性。ConRFT通过离线和在线两个阶段,利用人类示范数据和一致性策略,解决了传统方法在真实环境中的挑战,增强了智能机械臂的精准性和泛化能力。
本文介绍了一种新型强化学习算法——群体序列策略优化(GSPO),旨在提升大型语言模型的训练稳定性和效率。GSPO通过基于序列概率定义重要性比率,解决了GRPO算法的稳定性问题,显著提高了Qwen3模型的性能。
本文研究了近端策略优化(PPO)中的优势估计不稳定性,提出了动态非线性缩放自适应调制优势估计方法AM-PPO,显著改善了奖励轨迹,促进了学习过程,减少了剪裁需求,具有广泛的应用潜力。
本研究提出了一种引导策略优化(GPO)框架,旨在解决部分可观察环境中强化学习的不确定性问题。该方法通过引导者与学习者的共同训练,理论上达到了与直接强化学习相当的最优性,并在多项任务中显著优于现有方法。
本研究提出了LLM-Explorer,利用大型语言模型分析学习状态,生成特定任务的探索策略并动态调整。实验结果显示,该方法在Atari和MuJoCo基准测试中平均提升表现37.27%。
本研究提出了Pass@K策略优化(PKPO)方法,解决了传统强化学习算法在样本独立优化中多样性不足的问题。该方法通过优化pass@k性能,提升了复杂任务中的学习能力。
本研究提出了StepSearch框架,旨在解决大型语言模型在复杂多跳问答中的知识获取问题。通过逐步近端策略优化,该框架显著优于传统方法,验证了细粒度监督的有效性。
本研究提出了一种新方法——行为约束策略梯度与负样本增强(BCPG-NSA),旨在优化大语言模型的推理能力。通过挖掘负样本中的反思和纠错信息,实验结果表明该方法在数学和编程推理基准测试中优于现有技术,提高了样本效率,并展现出良好的鲁棒性和可扩展性。
本研究提出了一种新框架,将度量学习与大型语言模型结合,用于生态建模评估。该方法提高了农作物生产力和二氧化碳通量预测的评估能力,解决了传统评估指标在捕捉生态过程时间模式方面的不足。
本研究提出了一种新算法,通过优势加权重要性采样训练平面目标条件策略,解决了离线目标条件强化学习中的稀疏奖励和折扣问题。该方法无需生成(子)目标空间模型,并在复杂长期任务中展现出超越现有技术的潜力。
本文提出了一种新方法LatentSeek,通过潜在空间实现实例级适应,显著提升大型语言模型的推理能力,在多个基准测试中超越现有方法,展现出高效性和可扩展性。
Government subsidies, investment incentives, and other industrial-policy actions have almost quadrupled since 2017. Here’s how business leaders can navigate the impact of industrial policy on...
本研究提出了一种新的稳健策略计算方法,解决了部分可观察马尔可夫决策过程(POMDP)中策略对环境扰动的稳健性问题。通过结合形式化验证与次梯度上升优化,实验结果表明该方法在多个基准测试中展现出更好的稳健性和泛化能力。
完成下面两步后,将自动完成登录并继续当前操作。