
Diffusion Policy笔记
内容提要
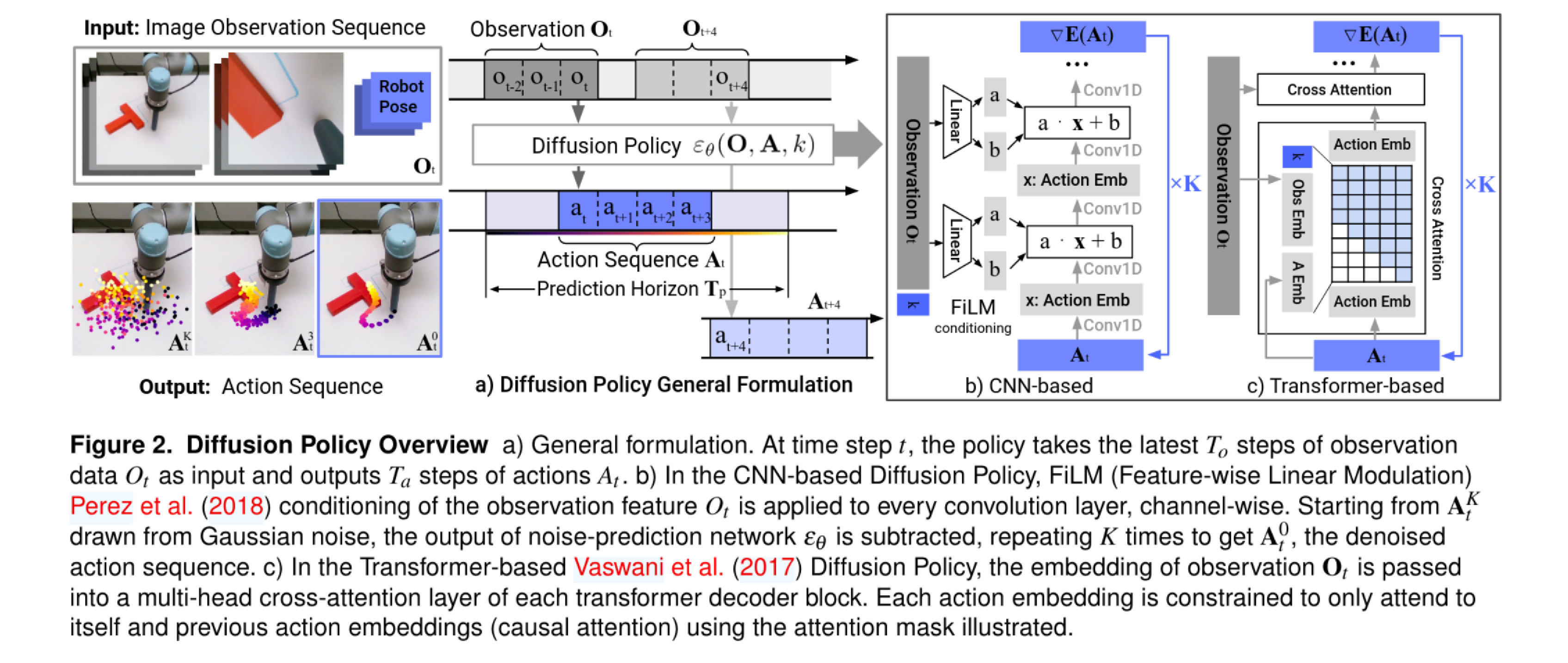
本文讨论了Diffusion Policy在机器人动作规划中的应用。通过神经网络预测噪声并逐步去噪,机器人能够生成精准的动作轨迹。尽管面临视觉遮挡和物理干扰,机器人依然能重新规划路径,展现出强大的适应能力。研究表明,该模型在学习物理系统动力学方面表现出色。
关键要点
-
Diffusion Policy通过神经网络预测噪声并逐步去噪,生成精准的动作轨迹。
-
机器人在面对视觉遮挡和物理干扰时,能够重新规划路径,展现出强大的适应能力。
-
模型在学习物理系统动力学方面表现出色,能够根据画面变化合成新的行为。
-
与传统控制器相比,Diffusion Policy在某些情况下能够实现类似的控制效果,表明其在隐式学习物理规律方面的能力。
延伸解读
Diffusion Policy的优势与局限
Diffusion Policy通过逐步去噪生成精准动作轨迹,展现出强大的适应能力。然而,该模型在处理复杂任务时可能面临训练难度大、超参数敏感等局限性。相比之下,传统控制器在某些情况下表现稳定,但缺乏灵活性。
应对干扰的能力
在实验中,Diffusion Policy展示了在视觉遮挡和物理干扰下的强大应对能力。机器人能够根据环境变化重新规划路径,这一特性在实际应用中尤为重要,尤其是在动态和不确定的环境中。
模型与物理规律的关系
研究表明,Diffusion Policy不仅仅是模仿动作,它在隐式学习物理系统的动力学规律。这一发现为机器人技术的发展提供了新的视角,强调了模型在理解和适应真实世界中的重要性。
延伸问答
Diffusion Policy是如何生成动作轨迹的?
Diffusion Policy通过神经网络预测噪声并逐步去噪,最终生成精准的动作轨迹。
机器人在面对视觉遮挡时如何应对?
机器人在视觉遮挡时依靠之前的序列规划,能够精准完成任务,尽管出现轻微抖动。
Diffusion Policy与传统控制器相比有什么优势?
Diffusion Policy在某些情况下能够实现类似的控制效果,并在隐式学习物理规律方面表现出色。
Diffusion Policy如何处理物理干扰?
在物理干扰下,机器人能够立即重新规划路径,甚至改变推的方向,确保任务完成。
Diffusion Policy在学习物理系统动力学方面表现如何?
Diffusion Policy在学习物理系统动力学方面表现出色,能够根据画面变化合成新的行为。
Diffusion Policy的训练过程是怎样的?
Diffusion Policy的训练过程包括生成高斯随机噪声序列,并通过多次迭代去噪,最终形成清晰的动作轨迹。
