
Dimple:一种用于高效可控文本生成的离散扩散多模态语言模型
内容提要
近年来,扩散模型在自然语言处理中的应用引起关注,发展出离散扩散语言模型(DLM)。DLM通过去噪生成文本,支持并行解码,提高生成速度和结构控制。新加坡国立大学的Dimple模型结合视觉编码器与扩散语言模型,采用自回归与扩散的两阶段训练,性能优于同规模自回归模型。
关键要点
-
扩散模型在自然语言处理中的应用引起关注,发展出离散扩散语言模型(DLM)。
-
DLM通过去噪生成文本,支持并行解码,提高生成速度和结构控制。
-
新加坡国立大学的Dimple模型结合视觉编码器与扩散语言模型,采用自回归与扩散的两阶段训练。
-
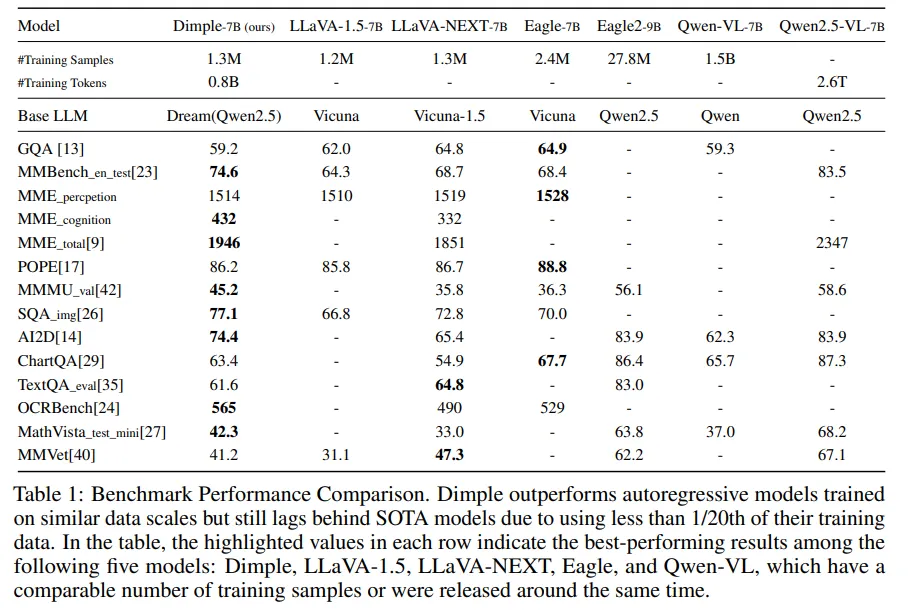
Dimple模型在基准测试中性能优于同规模自回归模型,提升了推理效率和生成灵活性。
-
Dimple的训练方法包括自回归训练和扩散训练,解决了扩散训练中的低效问题。
-
动态置信解码策略根据预测置信度调整标记更新,显著减少推理步骤。
-
Dimple通过结构先验实现了结构化且可控的输出,提供了对格式和长度的细粒度控制能力。
延伸解读
扩散模型的优势与挑战
离散扩散语言模型(DLM)在文本生成中展现出去噪和并行解码的优势,能够更好地控制生成结构。然而,当前大多数多模态大型语言模型仍依赖自回归方法,显示出扩散模型在实际应用中的挑战与局限。
Dimple模型的创新训练方法
Dimple模型采用自回归与扩散的两阶段训练方法,解决了扩散训练的不稳定性问题。这种混合策略不仅提高了生成效率,还增强了模型在多模态理解任务中的表现,值得关注其在实际应用中的潜力。
动态置信解码的实用性
Dimple引入的动态置信解码策略根据预测置信度调整标记更新,显著减少推理步骤。这一创新在提高生成速度的同时,保持了模型的性能,展示了在实际应用中优化推理过程的可能性。
延伸问答
Dimple模型的主要创新点是什么?
Dimple模型结合了视觉编码器与离散扩散语言模型,采用自回归与扩散的两阶段训练方法,显著提高了推理效率和生成灵活性。
Dimple模型如何提高文本生成的速度和控制能力?
Dimple模型通过去噪生成文本,支持并行解码,并利用动态置信解码策略,根据预测置信度调整标记更新,从而提高生成速度和结构控制能力。
Dimple模型与传统自回归模型相比有什么优势?
Dimple模型在基准测试中性能优于同规模自回归模型,提供了更快的生成速度和更好的结构控制能力。
Dimple模型的训练方法是怎样的?
Dimple模型采用两阶段训练方法,首先进行自回归训练以实现视觉-语言对齐,然后进行扩散训练以恢复生成能力。
Dimple模型在多模态理解任务中的表现如何?
Dimple模型在多模态理解任务中表现出强劲的性能,尽管在更大规模数据集上训练的模型表现更好,但其仍具竞争力。
Dimple模型如何解决扩散训练中的低效问题?
Dimple模型通过引入自回归训练与扩散训练的结合,克服了纯扩散训练的不稳定性和性能问题。
