

💡
原文中文,约2600字,阅读约需6分钟。
📝
内容提要
艾伦人工智能研究所发布了OLMoASR,这是一套开放的自动语音识别模型,采用transformer架构,支持多种尺寸,适用于不同应用场景。其开放性促进了语音识别研究的可重复性和科学进步,为开发者提供灵活选择和领域适应的可能性。
🎯
关键要点
- 艾伦人工智能研究所发布了OLMoASR,这是开放的自动语音识别模型。
- OLMoASR采用transformer架构,支持多种尺寸,适用于不同应用场景。
- 发布了模型权重、训练数据标识符、过滤步骤、训练方案和基准脚本,促进了研究的透明性。
- 大多数现有语音识别模型缺乏透明度,影响了可重复性和科学进步。
- OLMoASR通过开放整个流程解决了语音识别研究中的透明性问题。
- 模型系列涵盖六种尺寸,允许开发者在推理成本和准确率之间进行权衡。
- OLMoASR-Pool包含约300万小时的音频和1700万份文本记录,数据来源于网络抓取。
- OLMoASR-Mix经过严格过滤,提供高质量的1M小时数据集,提升零样本泛化能力。
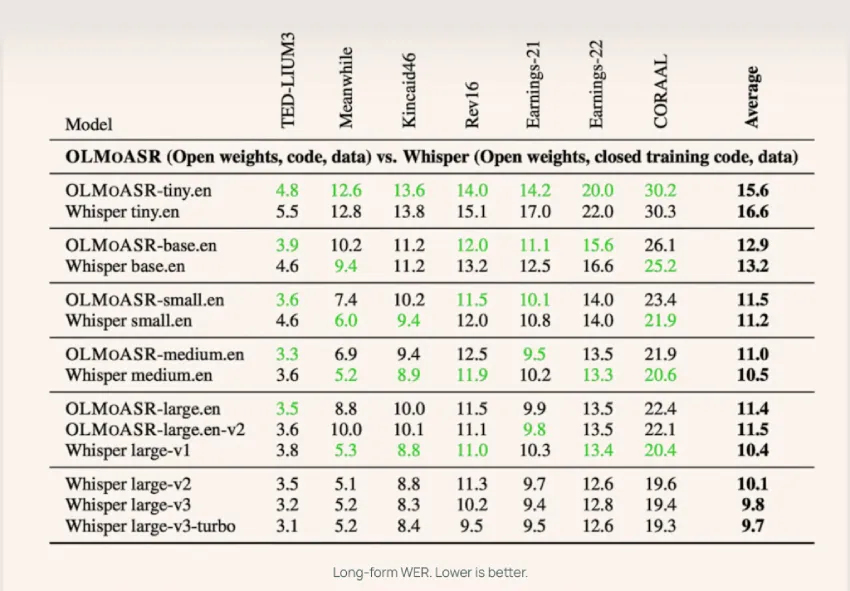
- AI2对OLMoASR进行了基准测试,结果与Whisper相当,显示出良好的性能。
- OLMoASR支持微调和领域适应,适用于医学、法律等专业领域。
- OLMoASR为学术研究和现实世界的AI开发提供了新的机会,促进了人机交互和多模式AI开发。
- 开放的训练数据和评估指标使OLMoASR成为未来ASR研究的标准化参考点。
- OLMoASR的发布为高质量语音识别的透明性和可重复性奠定了基础。
➡️
