
使用 Embedding 技术打造本地知识库助手
原文中文,约6700字,阅读约需16分钟。
📝
内容提要
本文介绍了使用Embedding技术实现本地知识库助手的方法,包括文档向量化、语义搜索、向量数据库存储、相似度计算和使用ChatGPT回答问题。还提到了度量方法、ANN算法和实际应用中的考虑因素。
🎯
关键要点
-
ChatGPT可以通过不同的提示语实现多种功能,包括问答、翻译和文本总结。
-
ChatGPT的局限性在于只能回答公开领域的知识,无法处理私有领域的信息。
-
Fine tuning和Embedding是实现私有知识库助手的两种方式,Fine tuning不再推荐用于知识问答任务。
-
Embedding技术适合知识问答任务,能够解决大模型的上下文限制问题。
-
Embedding技术可以将文本、图像等对象向量化,广泛应用于搜索和推荐。
-
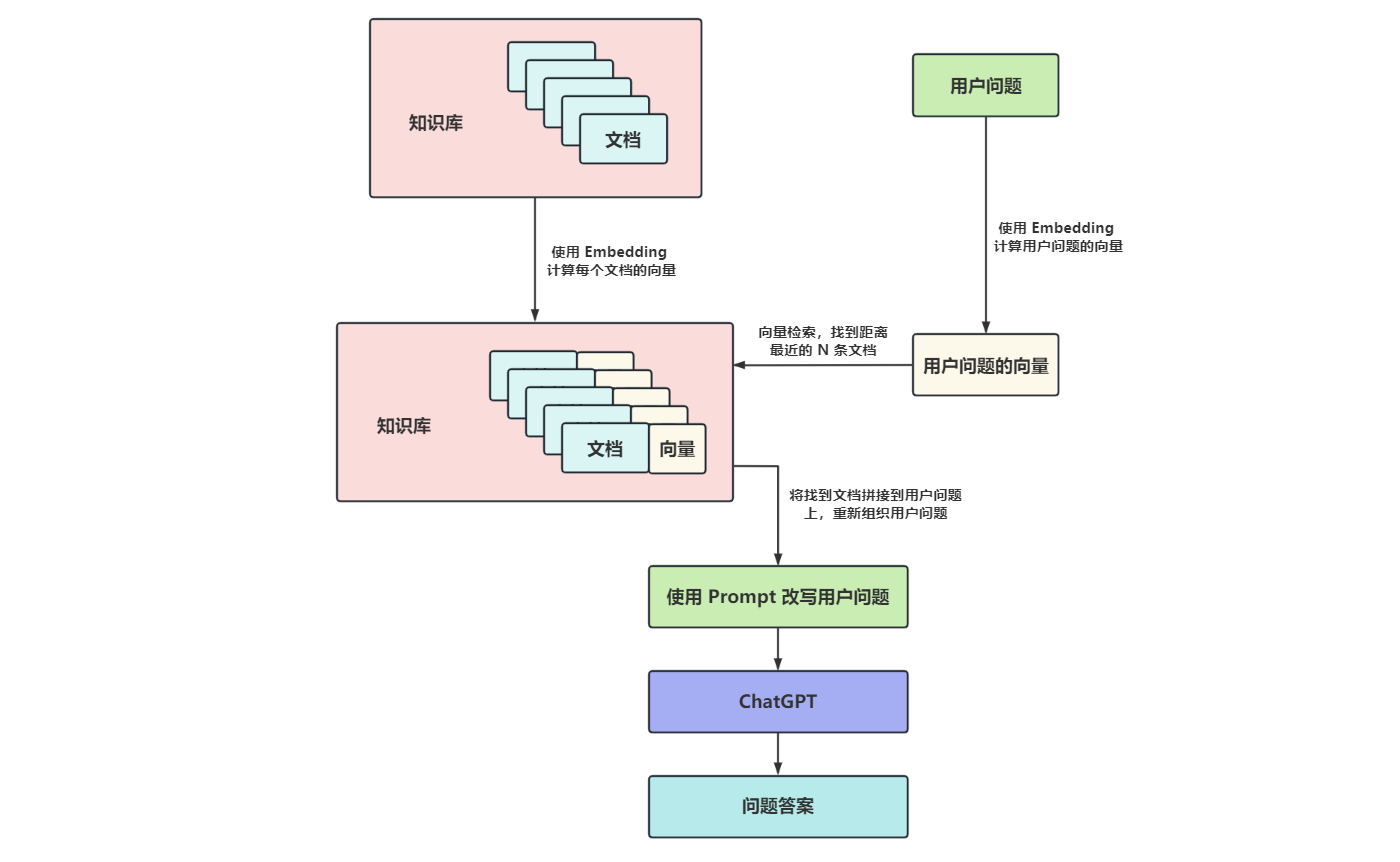
构建本地知识库需要对文档进行Embedding处理,包括计算和存储文档向量。
-
可以使用开源项目Sentence-Transformers和Towhee来进行Embedding处理。
-
向量数据库如Qdrant可以用于存储计算出的文档向量。
-
语义搜索通过Embedding技术实现,能够提高检索相关文档的准确性。
-
使用余弦相似度等方法计算向量之间的距离,以找到最相关的文档。
-
ANN算法用于加速向量检索,常见的算法包括HNSW和KD树。
-
最终将检索到的文档与用户问题组合,使用ChatGPT生成回答。
-
实现本地知识库助手的过程中需要考虑多种文档类型和数据问答的支持。
🏷️
